Adaptive Horizon Actor-Critic for Policy Learning in Contact-Rich Differentiable Simulation
{kind=link}
Abstract
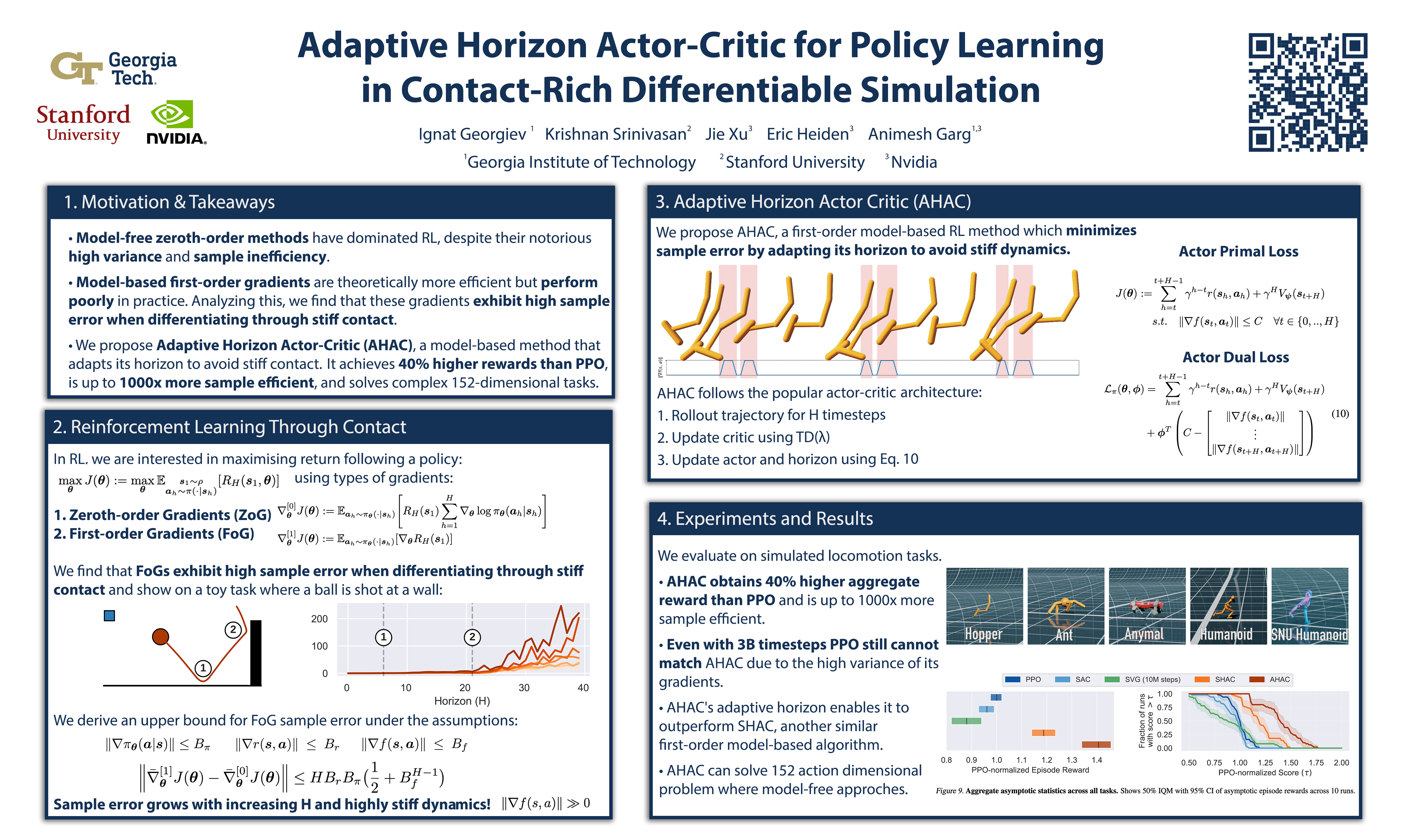
Model-Free Reinforcement Learning (MFRL), leveraging the policy gradient theorem, has demonstrated considerable success in continuous control tasks. However, these approaches are plagued by high gradient variance due to zeroth-order gradient estimation, resulting in suboptimal policies. Conversely, First-Order Model-Based Reinforcement Learning (FO-MBRL) methods employing differentiable simulation provide gradients with reduced variance but are susceptible to sampling error in scenarios involving stiff dynamics, such as physical contact. This paper investigates the source of this error and introduces Adaptive Horizon Actor-Critic (AHAC), an FO-MBRL algorithm that reduces gradient error by adapting the model-based horizon to avoid stiff dynamics. Empirical findings reveal that AHAC outperforms MFRL baselines, attaining 40% more reward across a set of locomotion tasks and efficiently scaling to high-dimensional control environments with improved wall-clock-time efficiency. adaptive-horizon-actor-critic.github.io