|
Test of Time Award
|
Test of Time
[ Hall C 1-3 ] AbstractWe evaluate whether features extracted from the activation of a deep convolutional network trained in a fully supervised fashion on a large, fixed set of object recognition tasks can be re- purposed to novel generic tasks. Our generic tasks may differ significantly from the originally trained tasks and there may be insufficient la- beled or unlabeled data to conventionally train or adapt a deep architecture to the new tasks. We in- vestigate and visualize the semantic clustering of deep convolutional features with respect to a va- riety of such tasks, including scene recognition, domain adaptation, and fine-grained recognition challenges. We compare the efficacy of relying on various network levels to define a fixed fea- ture, and report novel results that significantly outperform the state-of-the-art on several impor- tant vision challenges. We are releasing DeCAF, an open-source implementation of these deep convolutional activation features, along with all associated network parameters to enable vision researchers to be able to conduct experimenta- tion with deep representations across a range of visual concept learning paradigms. |
|
Best Paper
|
Oral
[ Straus 1-3 ] AbstractMachine learning (ML) datasets, often perceived as neutral, inherently encapsulate abstract and disputed social constructs. Dataset curators frequently employ value-laden terms such as diversity, bias, and quality to characterize datasets. Despite their prevalence, these terms lack clear definitions and validation. Our research explores the implications of this issue by analyzing "diversity" across 135 image and text datasets. Drawing from social sciences, we apply principles from measurement theory to identify considerations and offer recommendations for conceptualizing, operationalizing, and evaluating diversity in datasets. Our findings have broader implications for ML research, advocating for a more nuanced and precise approach to handling value-laden properties in dataset construction. |
|
Best Paper
|
Oral
[ Hall A8 ] 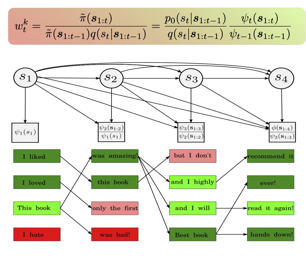
AbstractNumerous capability and safety techniques of Large Language Models (LLMs), including RLHF, automated red-teaming, prompt engineering, and infilling, can be cast as sampling from an unnormalized target distribution defined by a given reward or potential function over the full sequence. In this work, we leverage the rich toolkit of Sequential Monte Carlo (SMC) for these probabilistic inference problems. In particular, we use learned twist functions to estimate the expected future value of the potential at each timestep, which enables us to focus inference-time computation on promising partial sequences. We propose a novel contrastive method for learning the twist functions, and establish connections with the rich literature of soft reinforcement learning. As a complementary application of our twisted SMC framework, we present methods for evaluating the accuracy of language model inference techniques using novel bidirectional SMC bounds on the log partition function. These bounds can be used to estimate the KL divergence between the inference and target distributions in both directions. We apply our inference evaluation techniques to show that twisted SMC is effective for sampling undesirable outputs from a pretrained model (a useful component of harmlessness training and automated red-teaming), generating reviews with varied sentiment, and performing infilling tasks. |
|
Best Paper
|
Oral
[ Hall A8 ] AbstractWe present VideoPoet, a language model capable of synthesizing high-quality video from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting the ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/ |
|
Best Paper
|
Oral
[ Hall C 1-3 ] 
AbstractCommon methods for aligning large language models (LLMs) with desired behaviour heavily rely on human-labelled data. However, as models grow increasingly sophisticated, they will surpass human expertise, and the role of human evaluation will evolve into non-experts overseeing experts. In anticipation of this, we ask: can weaker models assess the correctness of stronger models? We investigate this question in an analogous setting, where stronger models (experts) possess the necessary information to answer questions and weaker models (non-experts) lack this information. The method we evaluate is debate, where two LLM experts each argue for a different answer, and a non-expert selects the answer. We find that debate consistently helps both non-expert models and humans answer questions, achieving 76% and 88% accuracy respectively (naive baselines obtain 48% and 60%). Furthermore, optimising expert debaters for persuasiveness in an unsupervised manner improves non-expert ability to identify the truth in debates. Our results provide encouraging empirical evidence for the viability of aligning models with debate in the absence of ground truth. |
|
Best Paper
|
Poster
[ Hall C 4-9 ] AbstractMachine learning (ML) datasets, often perceived as neutral, inherently encapsulate abstract and disputed social constructs. Dataset curators frequently employ value-laden terms such as diversity, bias, and quality to characterize datasets. Despite their prevalence, these terms lack clear definitions and validation. Our research explores the implications of this issue by analyzing "diversity" across 135 image and text datasets. Drawing from social sciences, we apply principles from measurement theory to identify considerations and offer recommendations for conceptualizing, operationalizing, and evaluating diversity in datasets. Our findings have broader implications for ML research, advocating for a more nuanced and precise approach to handling value-laden properties in dataset construction. |
|
Best Paper
|
Oral
[ Hall A2 ] Abstract
We introduce the first model-stealing attack that extracts precise, nontrivial information from black-box production language models like OpenAI's ChatGPT or Google's PaLM-2. Specifically, our attack recovers the embedding projection layer (up to symmetries) of a transformer model, given typical API access. For under $20 USD, our attack extracts the entire projection matrix of OpenAI's Ada and Babbage language models. We thereby confirm, for the first time, that these black-box models have a hidden dimension of 1024 and 2048, respectively. We also recover the exact hidden dimension size of the GPT-3.5-turbo model, and estimate it would cost under \\$2,000 in queries to recover the entire projection matrix. We conclude with potential defenses and mitigations, and discuss the implications of possible future work that could extend our attack.
|
|
Best Paper
|
Poster
[ Hall C 4-9 ] AbstractDiffusion models create data from noise by inverting the forward paths of data towards noise and have emerged as a powerful generative modeling technique for high-dimensional, perceptual data such as images and videos. Rectified flow is a recent generative model formulation that connects data and noise in a straight line. Despite its better theoretical properties and conceptual simplicity, it is not yet decisively established as standard practice. In this work, we improve existing noise sampling techniques for training rectified flow models by biasing them towards perceptually relevant scales. Through a large-scale study, we demonstrate the superior performance of this approach compared to established diffusion formulations for high-resolution text-to-image synthesis. Additionally, we present a novel transformer-based architecture for text-to-image generation that uses separate weights for the two modalities and enables a bidirectional flow of information between image and text tokens, improving text comprehension, typography, and human preference ratings. We demonstrate that this architecture follows predictable scaling trends and correlates lower validation loss to improved text-to-image synthesis as measured by various metrics and human evaluations. Our largest models outperform state-of-the-art models. Stability AI is considering making experimental data, code, and model weights publicly available. |
|
Best Paper
|
Poster
[ Hall C 4-9 ] AbstractThe performance of differentially private machine learning can be boosted significantly by leveraging the transfer learning capabilities of non-private models pretrained on large public datasets. We critically review this approach. We primarily question whether the use of large Web-scraped datasets should be viewed as differential-privacy-preserving. We further scrutinize whether existing machine learning benchmarks are appropriate for measuring the ability of pretrained models to generalize to sensitive domains. Finally, we observe that reliance on large pretrained models may lose other forms of privacy, requiring data to be outsourced to a more compute-powerful third party. |
|
Best Paper
|
Poster
[ Hall C 4-9 ] AbstractWe present VideoPoet, a language model capable of synthesizing high-quality video from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting the ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/ |
|
Best Paper
|
Oral
[ Hall A1 ] Abstract
Despite their groundbreaking performance for many generative modeling tasks, diffusion models have fallen short on discrete data domains such as natural language. Crucially, standard diffusion models rely on the well-established theory of score matching, but efforts to generalize this to discrete structures have not yielded the same empirical gains. In this work, we bridge this gap by proposing score entropy, a novel loss that naturally extends score matching to discrete spaces, integrates seamlessly to build discrete diffusion models, and significantly boosts performance. Experimentally, we test our Score Entropy Discrete Diffusion models (SEDD) on standard language modeling tasks. For comparable model sizes, SEDD beats existing language diffusion paradigms (reducing perplexity by $25$-$75$%) and is competitive with autoregressive models, in particular outperforming GPT-2. Furthermore, compared to autoregressive mdoels, SEDD generates faithful text without requiring distribution annealing techniques like temperature scaling (around $6$-$8\times$ better generative perplexity than un-annealed GPT-2), can trade compute and quality (similar quality with $32\times$ fewer network evaluations), and enables controllable infilling (matching nucleus sampling quality while enabling other strategies besides left to right prompting).
|
|
Best Paper
|
Poster
[ Hall C 4-9 ]
AbstractNumerous capability and safety techniques of Large Language Models (LLMs), including RLHF, automated red-teaming, prompt engineering, and infilling, can be cast as sampling from an unnormalized target distribution defined by a given reward or potential function over the full sequence. In this work, we leverage the rich toolkit of Sequential Monte Carlo (SMC) for these probabilistic inference problems. In particular, we use learned twist functions to estimate the expected future value of the potential at each timestep, which enables us to focus inference-time computation on promising partial sequences. We propose a novel contrastive method for learning the twist functions, and establish connections with the rich literature of soft reinforcement learning. As a complementary application of our twisted SMC framework, we present methods for evaluating the accuracy of language model inference techniques using novel bidirectional SMC bounds on the log partition function. These bounds can be used to estimate the KL divergence between the inference and target distributions in both directions. We apply our inference evaluation techniques to show that twisted SMC is effective for sampling undesirable outputs from a pretrained model (a useful component of harmlessness training and automated red-teaming), generating reviews with varied sentiment, and performing infilling tasks. |
|
Best Paper
|
Poster
[ Hall C 4-9 ] Abstract
We introduce the first model-stealing attack that extracts precise, nontrivial information from black-box production language models like OpenAI's ChatGPT or Google's PaLM-2. Specifically, our attack recovers the embedding projection layer (up to symmetries) of a transformer model, given typical API access. For under $20 USD, our attack extracts the entire projection matrix of OpenAI's Ada and Babbage language models. We thereby confirm, for the first time, that these black-box models have a hidden dimension of 1024 and 2048, respectively. We also recover the exact hidden dimension size of the GPT-3.5-turbo model, and estimate it would cost under \\$2,000 in queries to recover the entire projection matrix. We conclude with potential defenses and mitigations, and discuss the implications of possible future work that could extend our attack.
|
|
Best Paper
|
Oral
[ Hall A8 ] AbstractWe introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future. |
|
Best Paper
|
Oral
[ Hall A1 ] AbstractDiffusion models create data from noise by inverting the forward paths of data towards noise and have emerged as a powerful generative modeling technique for high-dimensional, perceptual data such as images and videos. Rectified flow is a recent generative model formulation that connects data and noise in a straight line. Despite its better theoretical properties and conceptual simplicity, it is not yet decisively established as standard practice. In this work, we improve existing noise sampling techniques for training rectified flow models by biasing them towards perceptually relevant scales. Through a large-scale study, we demonstrate the superior performance of this approach compared to established diffusion formulations for high-resolution text-to-image synthesis. Additionally, we present a novel transformer-based architecture for text-to-image generation that uses separate weights for the two modalities and enables a bidirectional flow of information between image and text tokens, improving text comprehension, typography, and human preference ratings. We demonstrate that this architecture follows predictable scaling trends and correlates lower validation loss to improved text-to-image synthesis as measured by various metrics and human evaluations. Our largest models outperform state-of-the-art models. Stability AI is considering making experimental data, code, and model weights publicly available. |
|
Best Paper
|
Poster
[ Hall C 4-9 ] Abstract
Despite their groundbreaking performance for many generative modeling tasks, diffusion models have fallen short on discrete data domains such as natural language. Crucially, standard diffusion models rely on the well-established theory of score matching, but efforts to generalize this to discrete structures have not yielded the same empirical gains. In this work, we bridge this gap by proposing score entropy, a novel loss that naturally extends score matching to discrete spaces, integrates seamlessly to build discrete diffusion models, and significantly boosts performance. Experimentally, we test our Score Entropy Discrete Diffusion models (SEDD) on standard language modeling tasks. For comparable model sizes, SEDD beats existing language diffusion paradigms (reducing perplexity by $25$-$75$%) and is competitive with autoregressive models, in particular outperforming GPT-2. Furthermore, compared to autoregressive mdoels, SEDD generates faithful text without requiring distribution annealing techniques like temperature scaling (around $6$-$8\times$ better generative perplexity than un-annealed GPT-2), can trade compute and quality (similar quality with $32\times$ fewer network evaluations), and enables controllable infilling (matching nucleus sampling quality while enabling other strategies besides left to right prompting).
|
|
Best Paper
|
Poster
[ Hall C 4-9 ] AbstractWe introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future. |
|
Best Paper
|
Poster
[ Hall C 4-9 ] 
Abstract
In this work, we investigate the interplay between memorization and learning in the context of *stochastic convex optimization* (SCO). We define memorization via the information a learning algorithm reveals about its training data points. We then quantify this information using the framework of conditional mutual information (CMI) proposed by Steinke and Zakynthinou (2020). Our main result is a precise characterization of the tradeoff between the accuracy of a learning algorithm and its CMI, answering an open question posed by Livni (2023). We show that, in the $L^2$ Lipschitz--bounded setting and under strong convexity, every learner with an excess error $\epsilon$ has CMI bounded below by $\Omega(1/\epsilon^2)$ and $\Omega(1/\epsilon)$, respectively. We further demonstrate the essential role of memorization in learning problems in SCO by designing an adversary capable of accurately identifying a significant fraction of the training samples in specific SCO problems. Finally, we enumerate several implications of our results, such as a limitation of generalization bounds based on CMI and the incompressibility of samples in SCO problems.
|
|
Best Paper
|
Oral
[ Hall A1 ] AbstractThe performance of differentially private machine learning can be boosted significantly by leveraging the transfer learning capabilities of non-private models pretrained on large public datasets. We critically review this approach. We primarily question whether the use of large Web-scraped datasets should be viewed as differential-privacy-preserving. We further scrutinize whether existing machine learning benchmarks are appropriate for measuring the ability of pretrained models to generalize to sensitive domains. Finally, we observe that reliance on large pretrained models may lose other forms of privacy, requiring data to be outsourced to a more compute-powerful third party. |
|
Best Paper
|
Poster
[ Hall C 4-9 ]
AbstractCommon methods for aligning large language models (LLMs) with desired behaviour heavily rely on human-labelled data. However, as models grow increasingly sophisticated, they will surpass human expertise, and the role of human evaluation will evolve into non-experts overseeing experts. In anticipation of this, we ask: can weaker models assess the correctness of stronger models? We investigate this question in an analogous setting, where stronger models (experts) possess the necessary information to answer questions and weaker models (non-experts) lack this information. The method we evaluate is debate, where two LLM experts each argue for a different answer, and a non-expert selects the answer. We find that debate consistently helps both non-expert models and humans answer questions, achieving 76% and 88% accuracy respectively (naive baselines obtain 48% and 60%). Furthermore, optimising expert debaters for persuasiveness in an unsupervised manner improves non-expert ability to identify the truth in debates. Our results provide encouraging empirical evidence for the viability of aligning models with debate in the absence of ground truth. |
|
Best Paper
|
Oral
[ Hall A1 ]
Abstract
In this work, we investigate the interplay between memorization and learning in the context of *stochastic convex optimization* (SCO). We define memorization via the information a learning algorithm reveals about its training data points. We then quantify this information using the framework of conditional mutual information (CMI) proposed by Steinke and Zakynthinou (2020). Our main result is a precise characterization of the tradeoff between the accuracy of a learning algorithm and its CMI, answering an open question posed by Livni (2023). We show that, in the $L^2$ Lipschitz--bounded setting and under strong convexity, every learner with an excess error $\epsilon$ has CMI bounded below by $\Omega(1/\epsilon^2)$ and $\Omega(1/\epsilon)$, respectively. We further demonstrate the essential role of memorization in learning problems in SCO by designing an adversary capable of accurately identifying a significant fraction of the training samples in specific SCO problems. Finally, we enumerate several implications of our results, such as a limitation of generalization bounds based on CMI and the incompressibility of samples in SCO problems.
|