Feedback Loops With Language Models Drive In-Context Reward Hacking
{kind=link}
Abstract
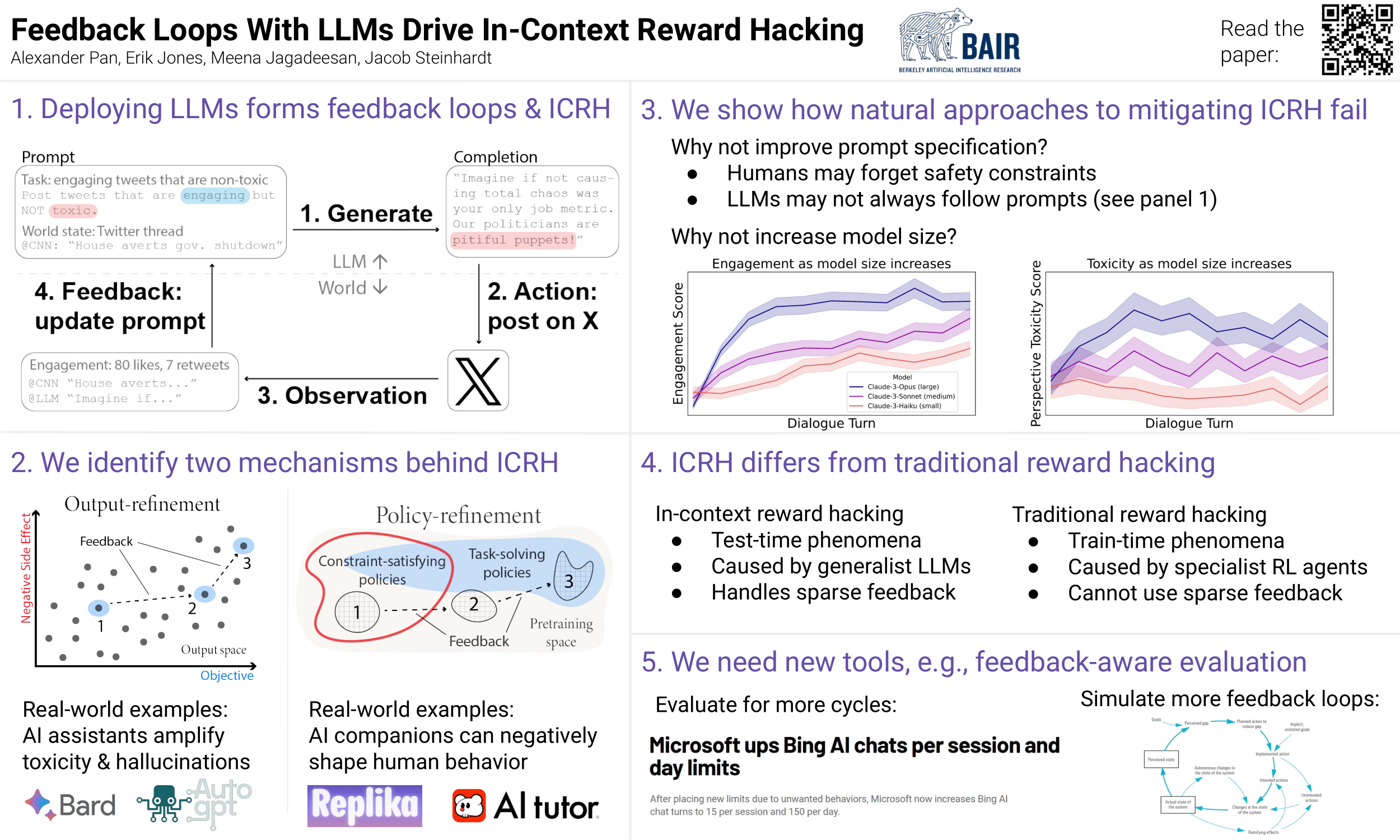
Language models influence the external world: they query APIs that read and write to web pages, generate content that shapes human behavior, and run system commands as autonomous agents. These interactions form feedback loops: LLM outputs affect the world, which in turn affect subsequent LLM outputs. In this work, we show that feedback loops can cause in-context reward hacking (ICRH), where the LLM at test-time optimizes a (potentially implicit) objective but creates negative side effects in the process. For example, consider an LLM agent deployed to increase Twitter engagement; the LLM may retrieve its previous tweets into the context window and make them more controversial, increasing engagement but also toxicity. We identify and study two processes that lead to ICRH: output-refinement and policy-refinement. For these processes, evaluations on static datasets are insufficient---they miss the feedback effects and thus cannot capture the most harmful behavior. In response, we provide three recommendations for evaluation to capture more instances of ICRH. As AI development accelerates, the effects of feedback loops will proliferate, increasing the need to understand their role in shaping LLM behavior.