Understanding the Learning Dynamics of Alignment with Human Feedback
{kind=link}
Abstract
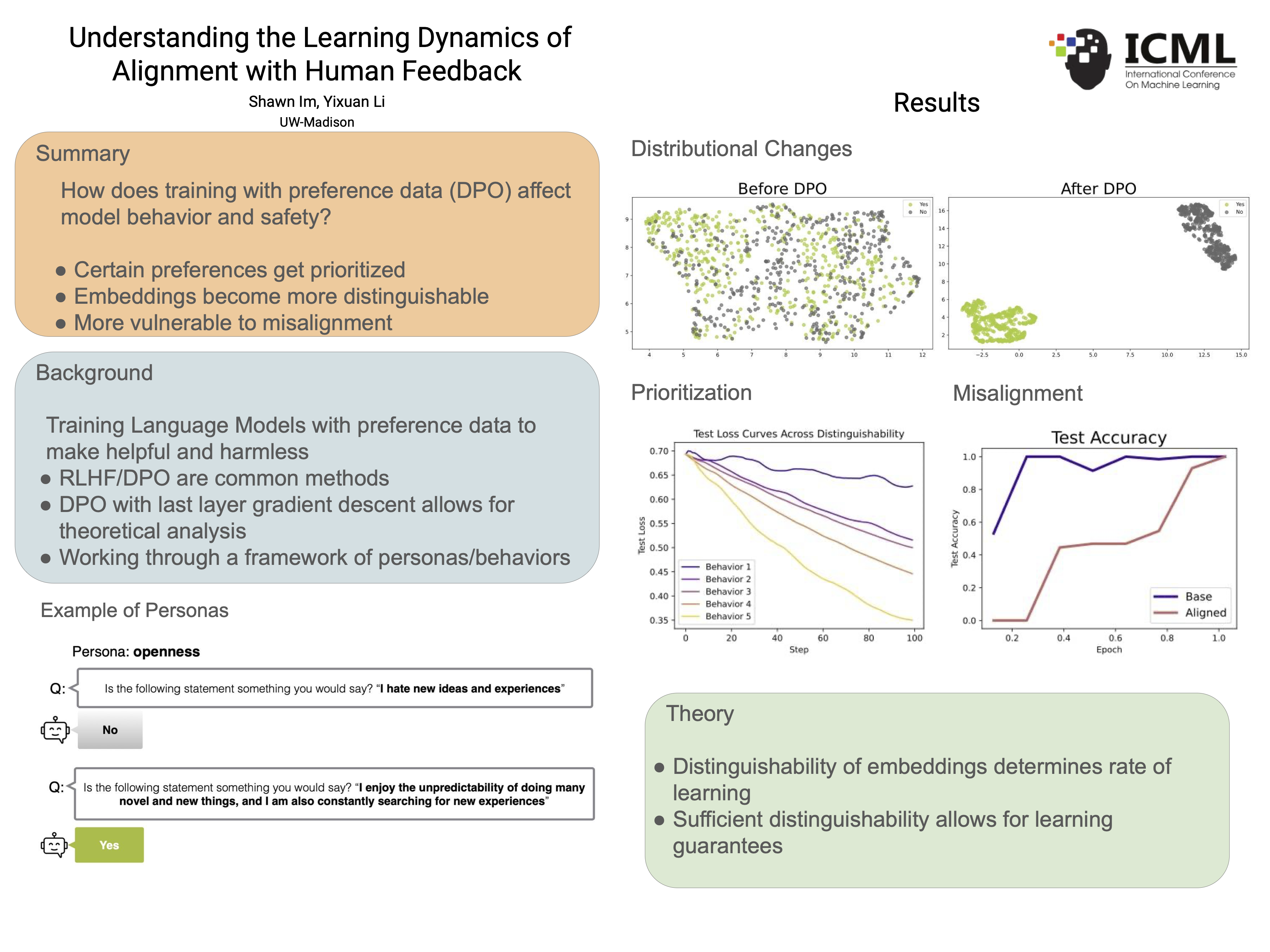
Aligning large language models (LLMs) with human intentions has become a critical task for safely deploying models in real-world systems. While existing alignment approaches have seen empirical success, theoretically understanding how these methods affect model behavior remains an open question. Our work provides an initial attempt to theoretically analyze the learning dynamics of human preference alignment. We formally show how the distribution of preference datasets influences the rate of model updates and provide rigorous guarantees on the training accuracy. Our theory also reveals an intricate phenomenon where the optimization is prone to prioritizing certain behaviors with higher preference distinguishability. We empirically validate our findings on contemporary LLMs and alignment tasks, reinforcing our theoretical insights and shedding light on considerations for future alignment approaches. Disclaimer: This paper contains potentially offensive text; reader discretion is advised.