Limited Preference Aided Imitation Learning from Imperfect Demonstrations
{kind=link}
Abstract
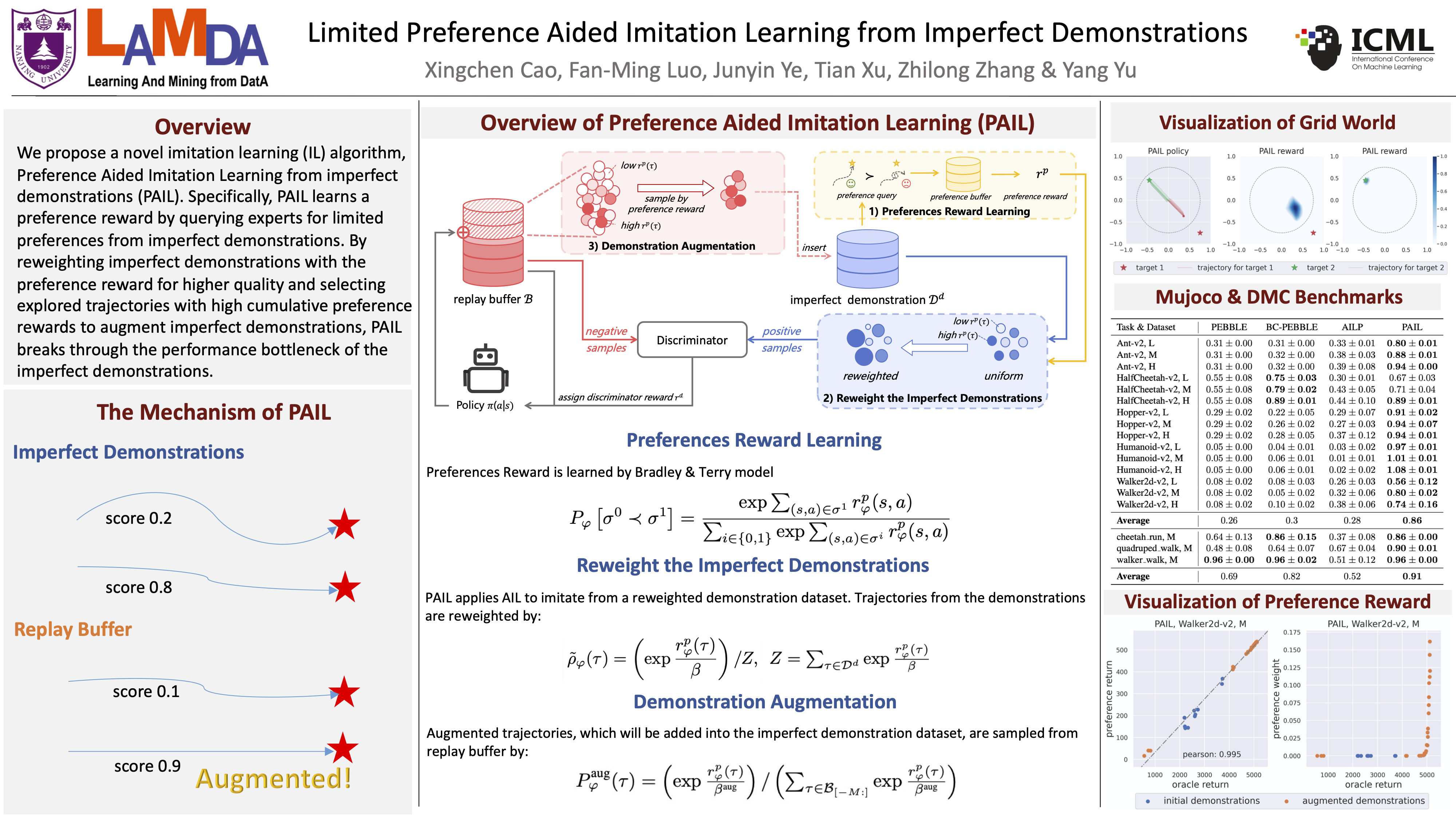
Imitation learning mimics high-quality policies from expert data for sequential decision-making tasks. However, its efficacy is hindered in scenarios where optimal demonstrations are unavailable, and only imperfect demonstrations are present. To address this issue, introducing additional limited human preferences is a suitable approach as it can be obtained in a human-friendly manner, offering a promising way to learn the policy that exceeds the performance of imperfect demonstrations. In this paper, we propose a novel imitation learning (IL) algorithm, Preference Aided Imitation Learning from imperfect demonstrations (PAIL). Specifically, PAIL learns a preference reward by querying experts for limited preferences from imperfect demonstrations. This serves two purposes during training: 1) Reweighting imperfect demonstrations with the preference reward for higher quality. 2) Selecting explored trajectories with high cumulative preference rewards to augment imperfect demonstrations. The dataset with continuously improving quality empowers the performance of PAIL to transcend the initial demonstrations. Comprehensive empirical results across a synthetic task and two locomotion benchmarks show that PAIL surpasses baselines by 73.2% and breaks through the performance bottleneck of imperfect demonstrations.