Self-Consistency Training for Density-Functional-Theory Hamiltonian Prediction
{kind=link}
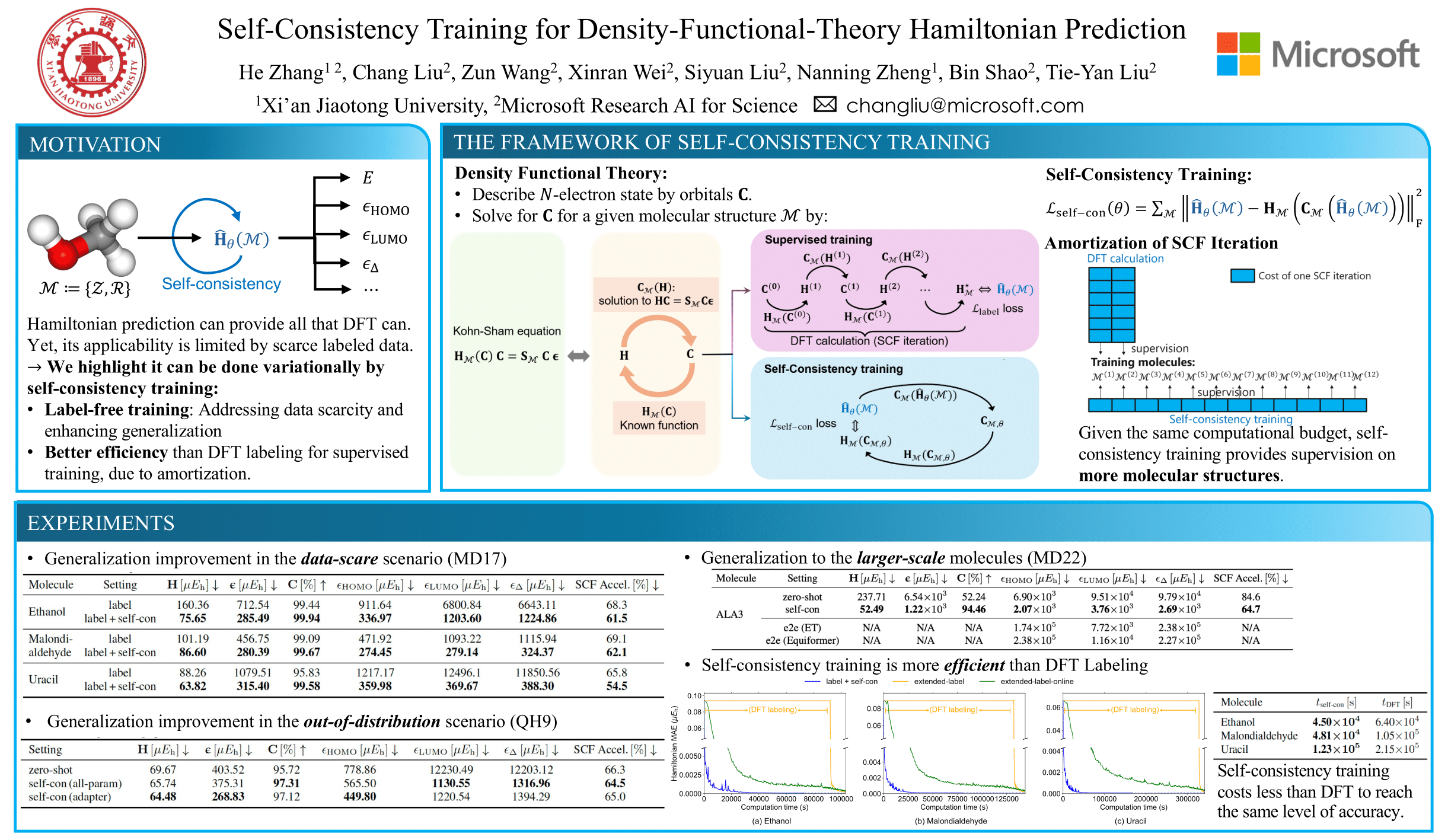
Abstract
Predicting the mean-field Hamiltonian matrix in density functional theory is a fundamental formulation to leverage machine learning for solving molecular science problems. Yet, its applicability is limited by insufficient labeled data for training. In this work, we highlight that Hamiltonian prediction possesses a self-consistency principle, based on which we propose self-consistency training, an exact training method that does not require labeled data. It distinguishes the task from predicting other molecular properties by the following benefits: (1) it enables the model to be trained on a large amount of unlabeled data, hence addresses the data scarcity challenge and enhances generalization; (2) it is more efficient than running DFT to generate labels for supervised training, since it amortizes DFT calculation over a set of queries. We empirically demonstrate the better generalization in data-scarce and out-of-distribution scenarios, and the better efficiency over DFT labeling. These benefits push forward the applicability of Hamiltonian prediction to an ever-larger scale.