RL-VLM-F: Reinforcement Learning from Vision Language Foundation Model Feedback
{kind=link}
Abstract
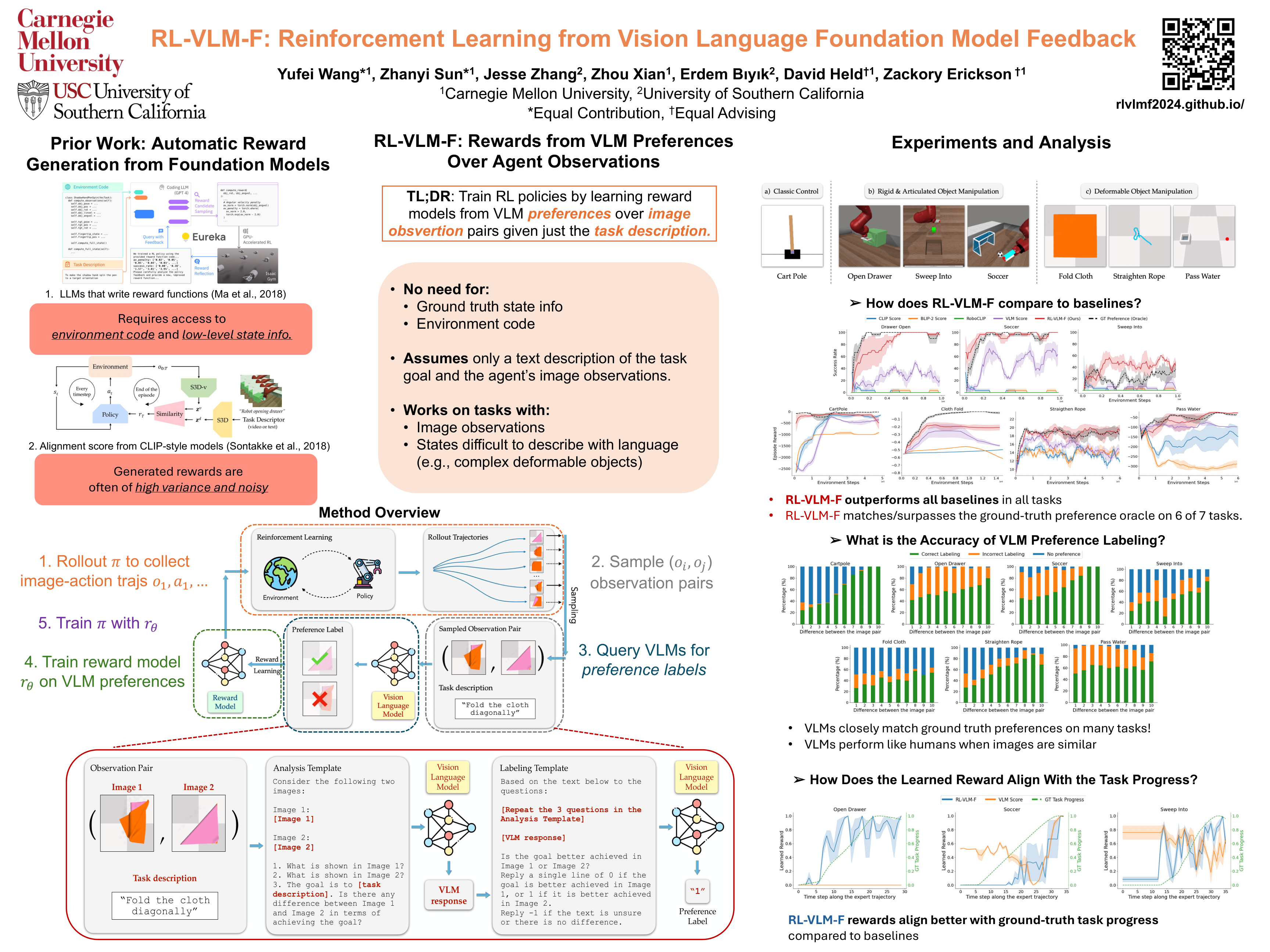
Reward engineering has long been a challenge in Reinforcement Learning (RL) research, as it often requires extensive human effort and iterative processes of trial-and-error to design effective reward functions. In this paper, we propose RL-VLM-F, a method that automatically generates reward functions for agents to learn new tasks, using only a text description of the task goal and the agent's visual observations, by leveraging feedbacks from vision language foundation models (VLMs). The key to our approach is to query these models to give preferences over pairs of the agent's image observations based on the text description of the task goal, and then learn a reward function from the preference labels, rather than directly prompting these models to output a raw reward score, which can be noisy and inconsistent. We demonstrate that RL-VLM-F successfully produces effective rewards and policies across various domains — including classic control, as well as manipulation of rigid, articulated, and deformable objects — without the need for human supervision, outperforming prior methods that use large pretrained models for reward generation under the same assumptions. Videos can be found on our project website: https://rlvlmf2024.github.io/