BRAIn: Bayesian Reward-conditioned Amortized Inference for natural language generation from feedback
{kind=link}
Abstract
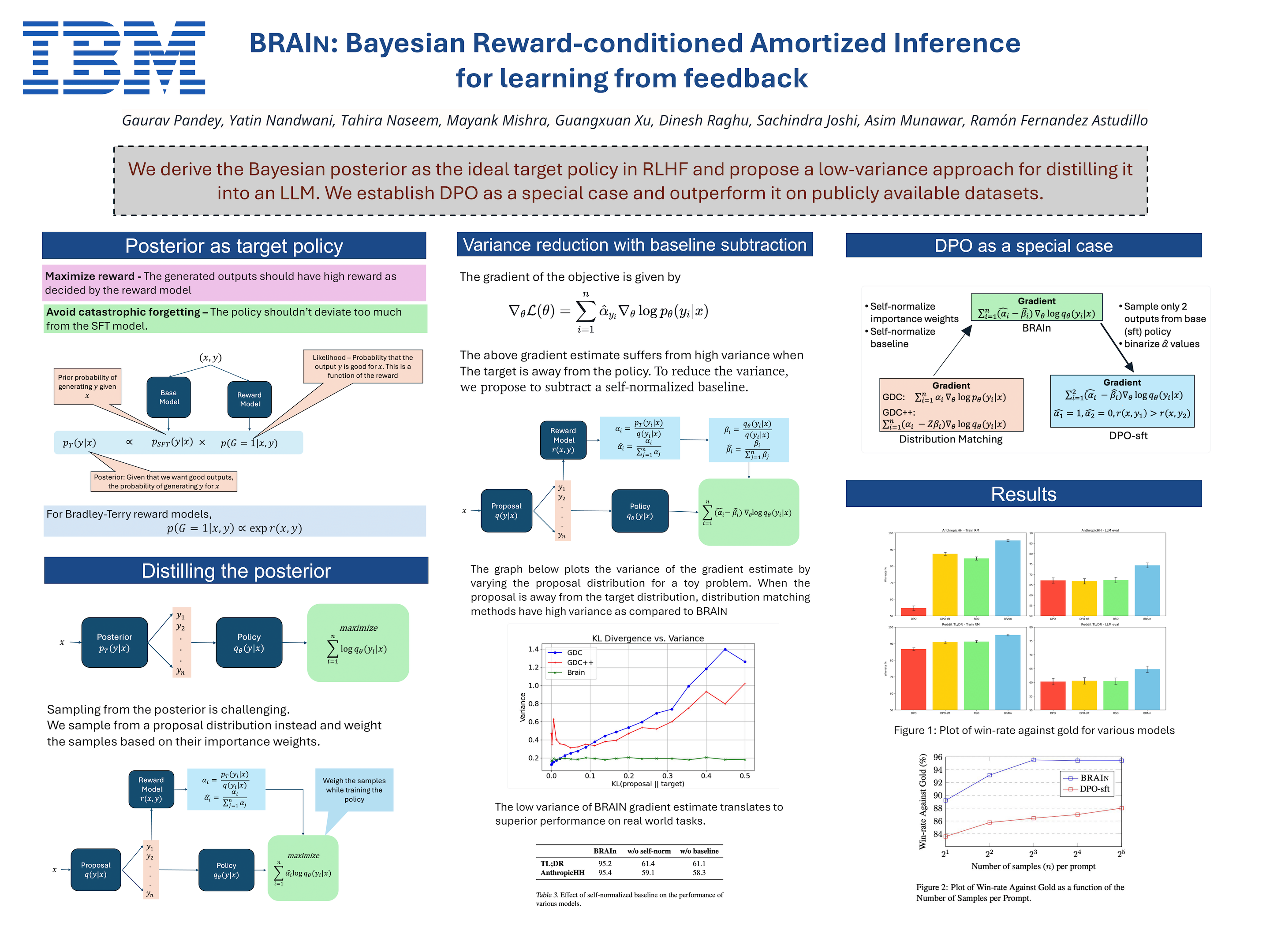
Distribution matching methods for language model alignment such as Generation with Distributional Control (GDC) and Distributional Policy Gradient (DPG) have not received the same level of attention in reinforcement learning from human feedback (RLHF) as contrastive methods such as Sequence Likelihood Calibration (SLiC), Direct Preference Optimization (DPO) and its variants. We identify high variance of the gradient estimate as the primary reason for the lack of success of these methods and propose a self-normalized baseline to reduce the variance. We further generalize the target distribution in DPG, GDC and DPO by using Bayes' rule to define the reward-conditioned posterior. The resulting approach, referred to as BRAIn - Bayesian Reward-conditioned Amortized Inference acts as a bridge between distribution matching methods and DPO and significantly outperforms prior art in summarization and Antropic HH tasks.