EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
{kind=link}
Abstract
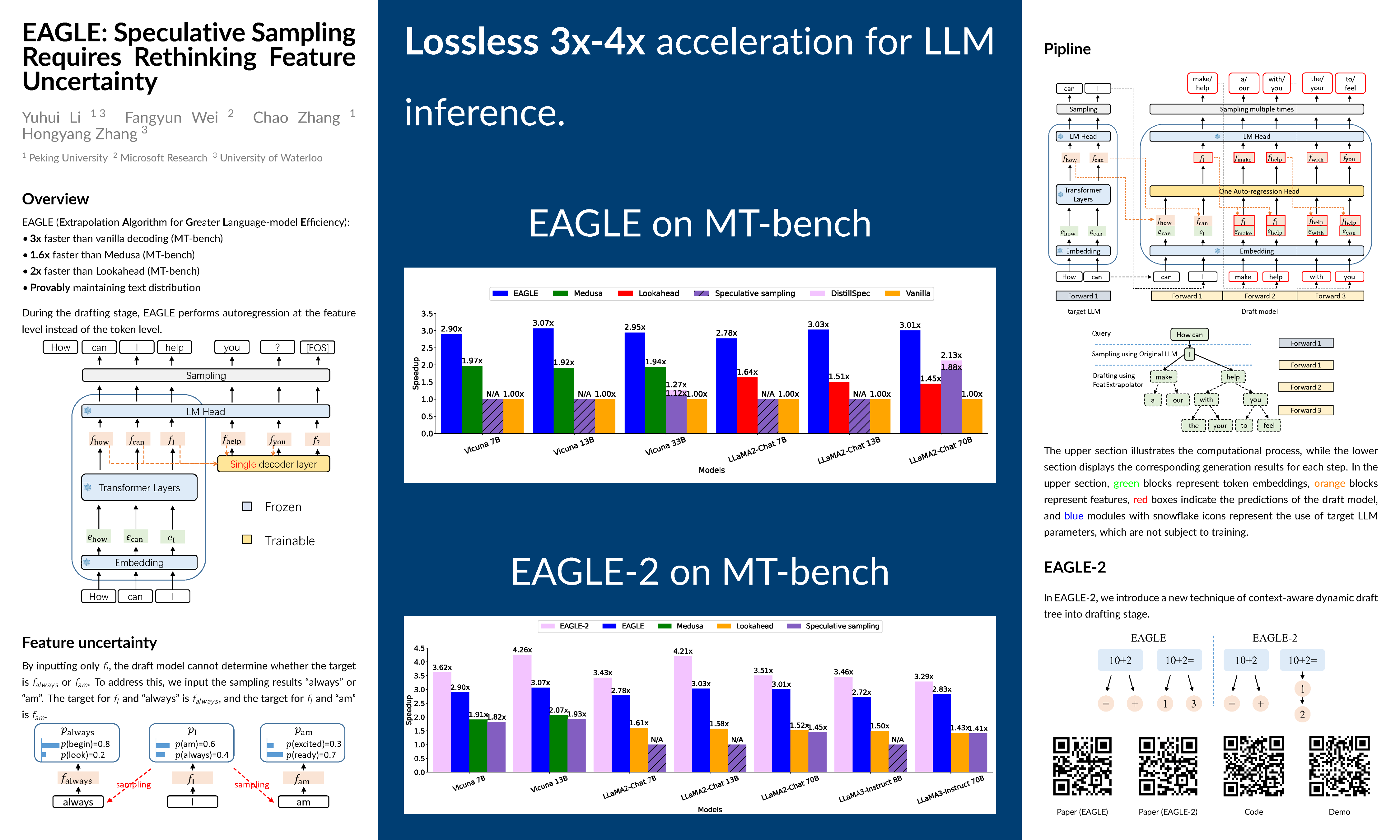
Autoregressive decoding makes the inference of Large Language Models (LLMs) time-consuming. In this paper, we reconsider speculative sampling and derive two key observations. Firstly, autoregression at the feature (second-to-top-layer) level is more straightforward than at the token level. Secondly, the inherent uncertainty in feature (second-to-top-layer) level autoregression constrains its performance. Based on these insights, we introduce EAGLE (Extrapolation Algorithm for Greater Language-model Efficiency), a simple yet highly efficient speculative sampling framework. By incorporating a token sequence advanced by one time step, EAGLE effectively resolves the uncertainty, enabling precise second-to-top-layer feature prediction with minimal overhead. We conducted comprehensive evaluations of EAGLE, including all models from the Vicuna and LLaMA2-Chat series, the MoE model Mixtral 8x7B Instruct, and tasks in dialogue, code generation, mathematical reasoning, and instruction following. For LLaMA2-Chat 70B, EAGLE achieved a latency speedup ratio of 2.7x-3.5x, doubled throughput, while maintaining the distribution of the generated text.