HarmoDT: Harmony Multi-Task Decision Transformer for Offline Reinforcement Learning
{kind=link}
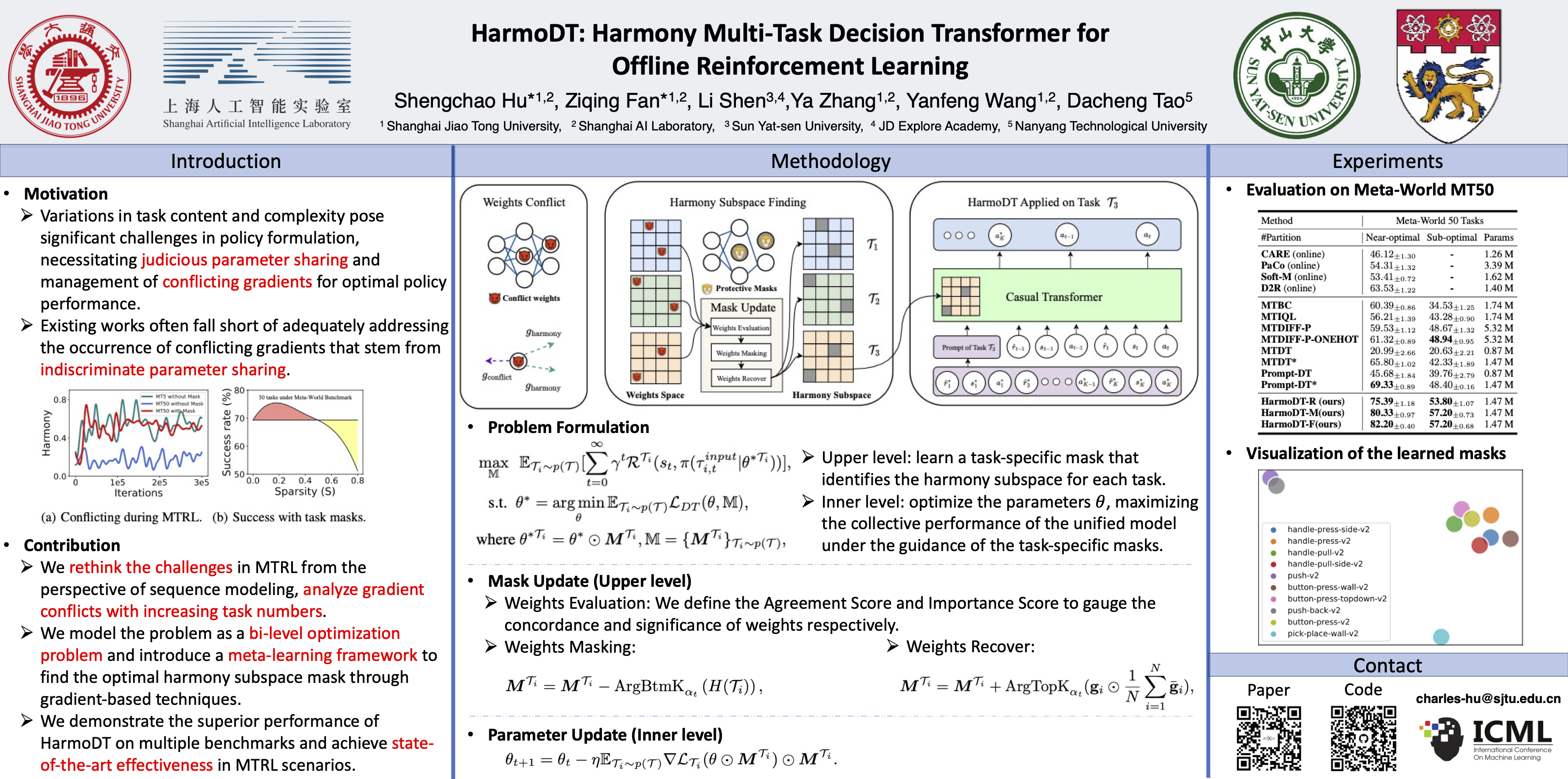
Abstract
The purpose of offline multi-task reinforcement learning (MTRL) is to develop a unified policy applicable to diverse tasks without the need for online environmental interaction. Recent advancements approach this through sequence modeling, leveraging the Transformer architecture's scalability and the benefits of parameter sharing to exploit task similarities. However, variations in task content and complexity pose significant challenges in policy formulation, necessitating judicious parameter sharing and management of conflicting gradients for optimal policy performance. In this work, we introduce the Harmony Multi-Task Decision Transformer (HarmoDT), a novel solution designed to identify an optimal harmony subspace of parameters for each task. We approach this as a bi-level optimization problem, employing a meta-learning framework that leverages gradient-based techniques. The upper level of this framework is dedicated to learning a task-specific mask that delineates the harmony subspace, while the inner level focuses on updating parameters to enhance the overall performance of the unified policy. Empirical evaluations on a series of benchmarks demonstrate the superiority of HarmoDT, verifying the effectiveness of our approach.