Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
{kind=link}
Abstract
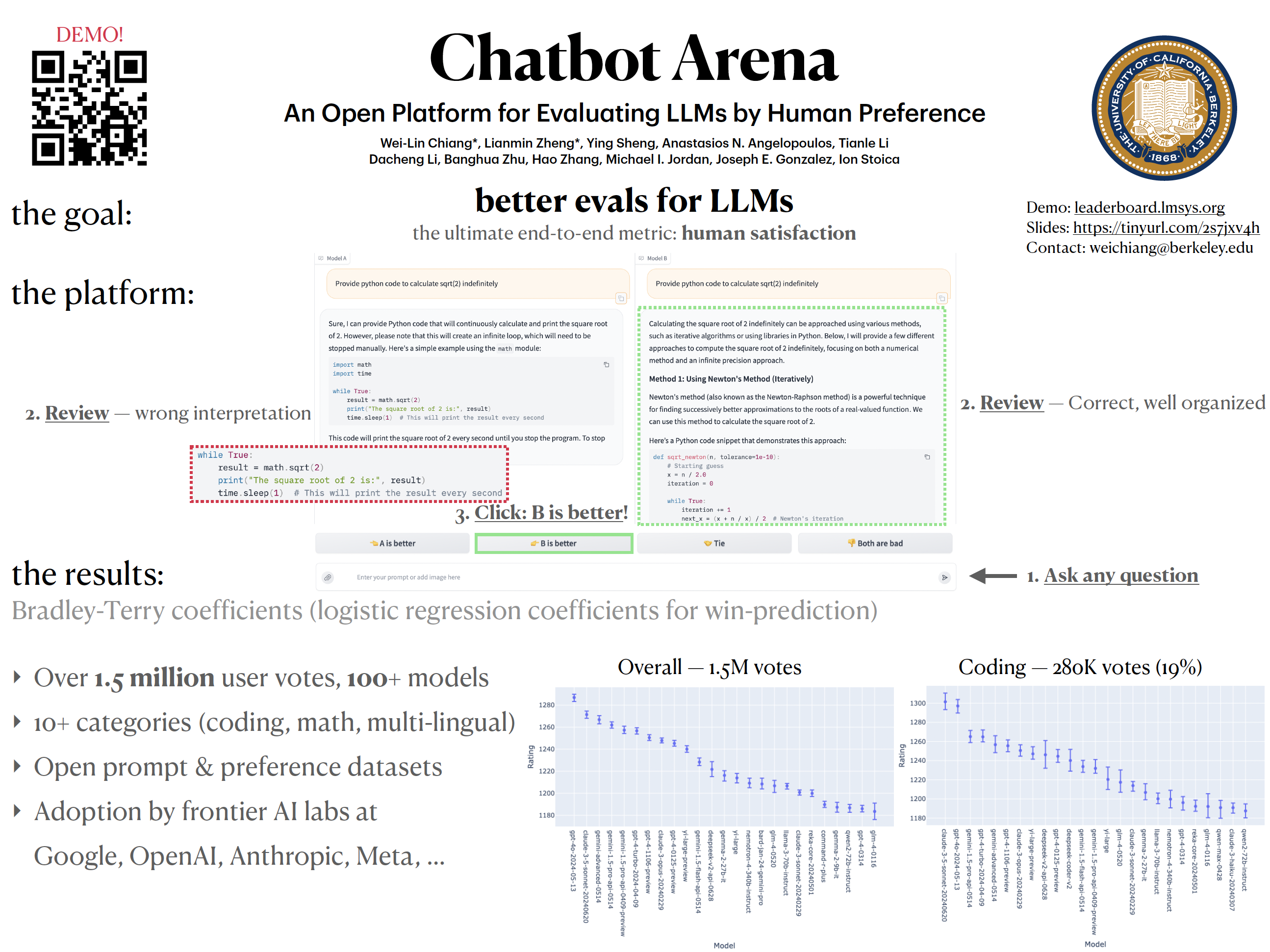
Large Language Models (LLMs) have unlocked new capabilities and applications; however, evaluating the alignment with human preferences still poses significant challenges. To address this issue, we introduce Chatbot Arena, an open platform for evaluating LLMs based on human preferences. Our methodology employs a pairwise comparison approach and leverages input from a diverse user base through crowdsourcing. The platform has been operational for several months, amassing over 240K votes. This paper describes the platform, analyzes the data we have collected so far, and explains the tried-and-true statistical methods we are using for efficient and accurate evaluation and ranking of models. We confirm that the crowdsourced questions are sufficiently diverse and discriminating and that the crowd-sourced human votes are in good agreement with those of expert raters. These analyses collectively establish a robust foundation for the credibility of Chatbot Arena. Because of its unique value and openness, Chatbot Arena has emerged as one of the most referenced LLM leaderboards, widely cited by leading LLM developers and companies. The platform is publicly available at https://chat.lmsys.org.