Learning to Stabilize Online Reinforcement Learning in Unbounded State Spaces
{kind=link}
Abstract
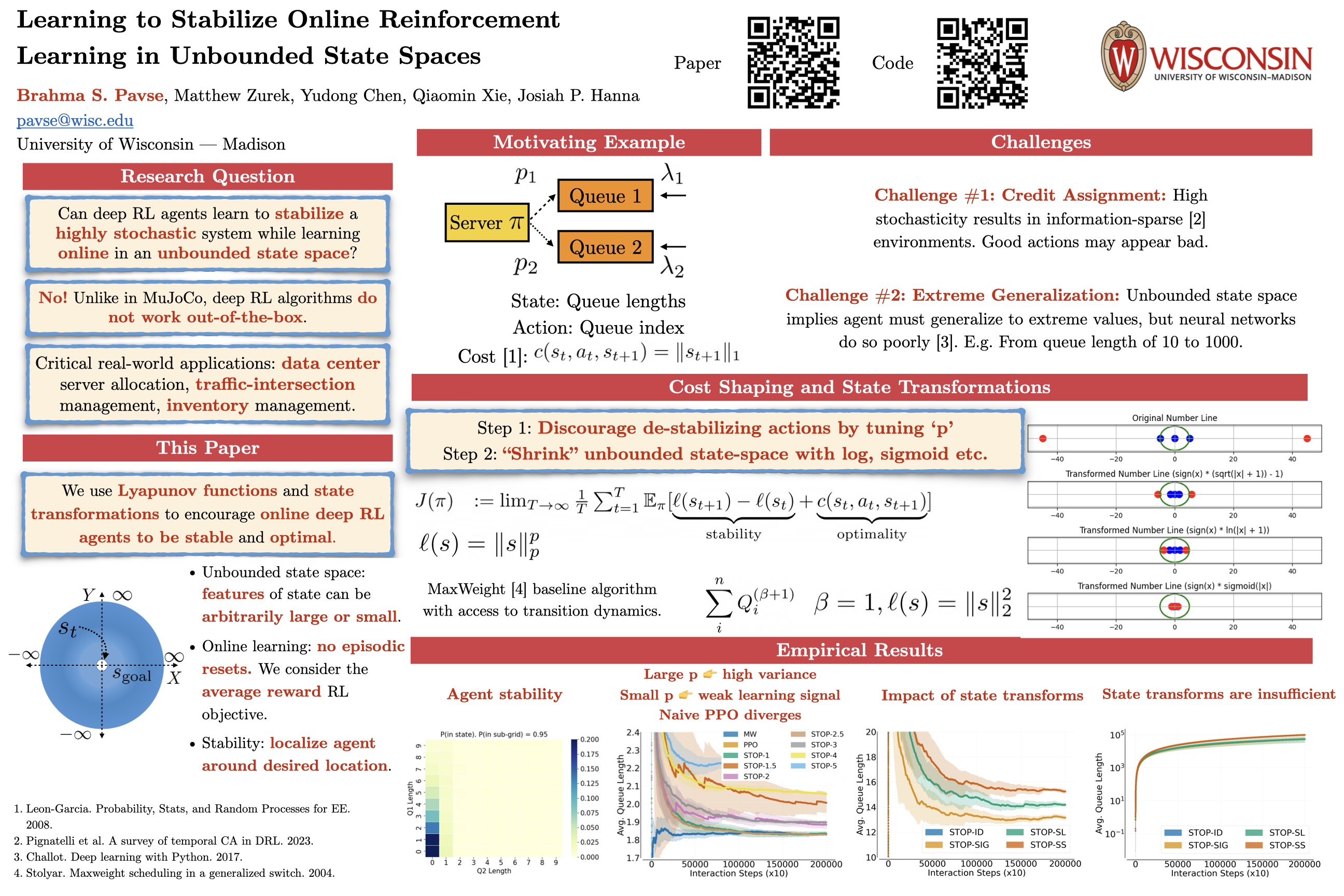
In many reinforcement learning (RL) applications, we want policies that reach desired states and then keep the controlled system within an acceptable region around the desired states over an indefinite period of time. This latter objective is called stability and is especially important when the state space is unbounded, such that the states can be arbitrarily far from each other and the agent can drift far away from the desired states. For example, in stochastic queuing networks, where queues of waiting jobs can grow without bound, the desired state is all-zero queue lengths. Here, a stable policy ensures queue lengths are finite while an optimal policy minimizes queue lengths. Since an optimal policy is also stable, one would expect that RL algorithms would implicitly give us stable policies. However, in this work, we find that deep RL algorithms that directly minimize the distance to the desired state during online training often result in unstable policies, i.e., policies that drift far away from the desired state. We attribute this instability to poor credit-assignment for destabilizing actions. We then introduce an approach based on two ideas: 1) a Lyapunov-based cost-shaping technique and 2) state transformations to the unbounded state space. We conduct an empirical study on various queueing networks and traffic signal control problems and find that our approach performs competitively against strong baselines with knowledge of the transition dynamics. Our code is available here: https://github.com/Badger-RL/STOP