Sub-token ViT Embedding via Stochastic Resonance Transformers
{kind=link}
Abstract
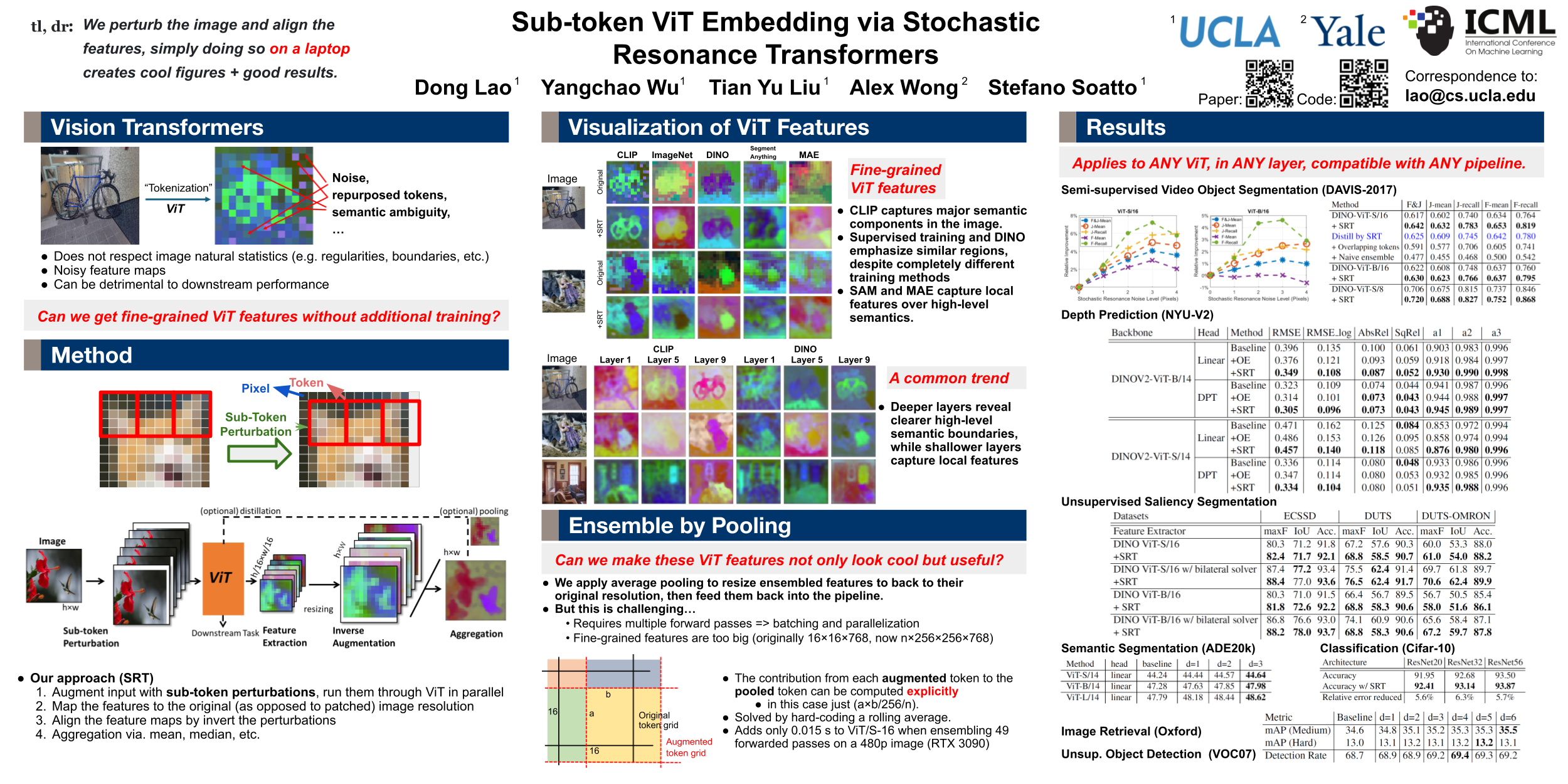
Vision Transformer (ViT) architectures represent images as collections of high-dimensional vectorized tokens, each corresponding to a rectangular non-overlapping patch. This representation trades spatial granularity for embedding dimensionality, and results in semantically rich but spatially coarsely quantized feature maps. In order to retrieve spatial details beneficial to fine-grained inference tasks we propose a training-free method inspired by "stochastic resonance." Specifically, we perform sub-token spatial transformations to the input data, and aggregate the resulting ViT features after applying the inverse transformation. The resulting "Stochastic Resonance Transformer" (SRT) retains the rich semantic information of the original representation, but grounds it on a finer-scale spatial domain, partly mitigating the coarse effect of spatial tokenization. SRT is applicable across any layer of any ViT architecture, consistently boosting performance on several tasks including segmentation, classification, depth estimation, and others by up to 14.9% without the need for any fine-tuning. Code: https://github.com/donglao/srt.