Seizing Serendipity: Exploiting the Value of Past Success in Off-Policy Actor-Critic
Tianying Ji ⋅ Yu Luo ⋅ Fuchun Sun ⋅ Xianyuan Zhan ⋅ Jianwei Zhang ⋅ Huazhe Xu
2024 Poster
{kind=link}
Abstract
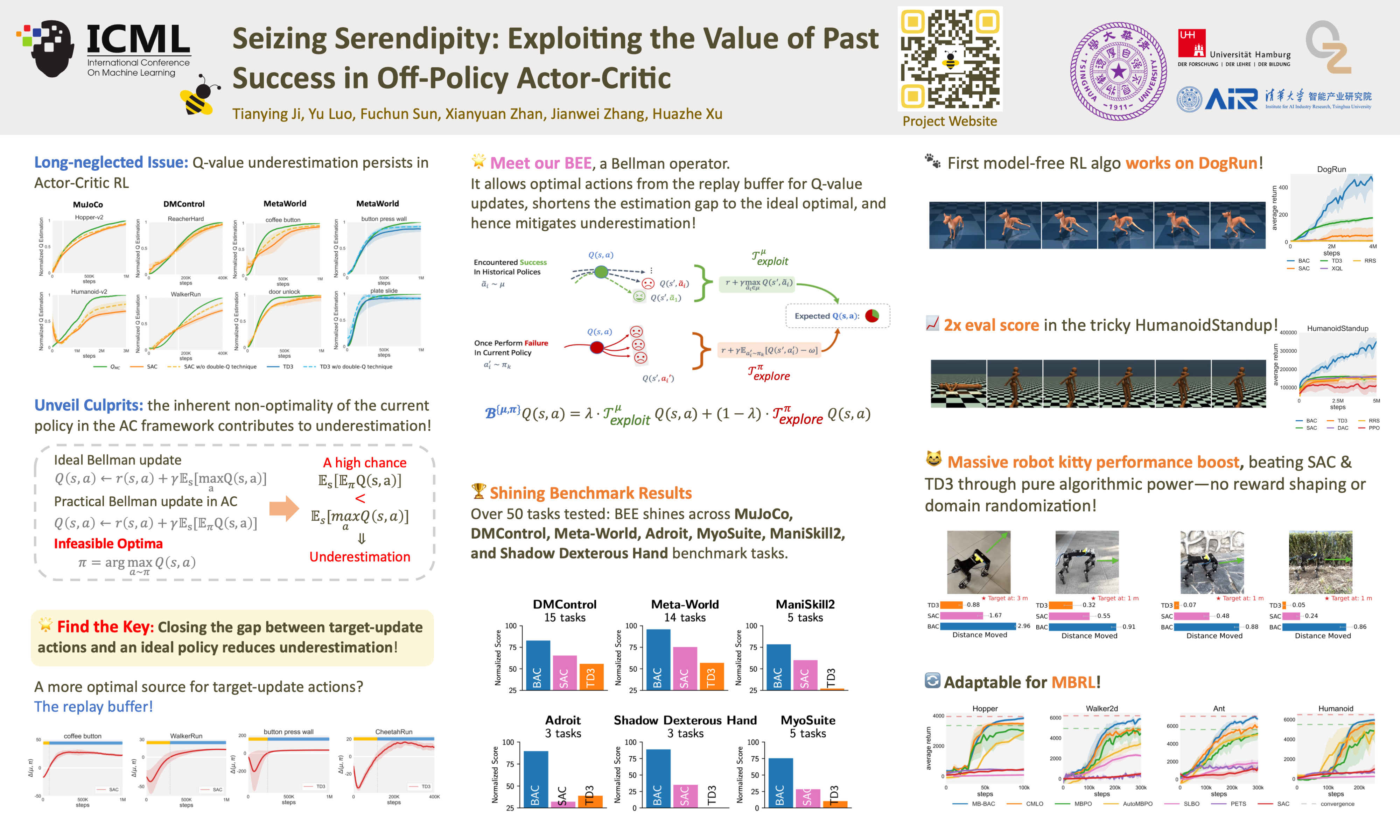
Learning high-quality $Q$-value functions plays a key role in the success of many modern off-policy deep reinforcement learning (RL) algorithms. Previous works primarily focus on addressing the value overestimation issue, an outcome of adopting function approximators and off-policy learning. Deviating from the common viewpoint, we observe that $Q$-values are often underestimated in the latter stage of the RL training process, potentially hindering policy learning and reducing sample efficiency. We find that such a long-neglected phenomenon is often related to the use of inferior actions from the current policy in Bellman updates as compared to the more optimal action samples in the replay buffer. We propose the Blended Exploitation and Exploration (BEE) operator, a simple yet effective approach that updates $Q$-value using both historical best-performing actions and the current policy. Based on BEE, the resulting practical algorithm BAC outperforms state-of-the-art methods in **over 50** continuous control tasks and achieves strong performance in failure-prone scenarios and **real-world robot** tasks. Benchmark results and videos are available at https://jity16.github.io/BEE/.
Video
Chat is not available.
Successful Page Load