Skill Set Optimization: Reinforcing Language Model Behavior via Transferable Skills
{kind=link}
Abstract
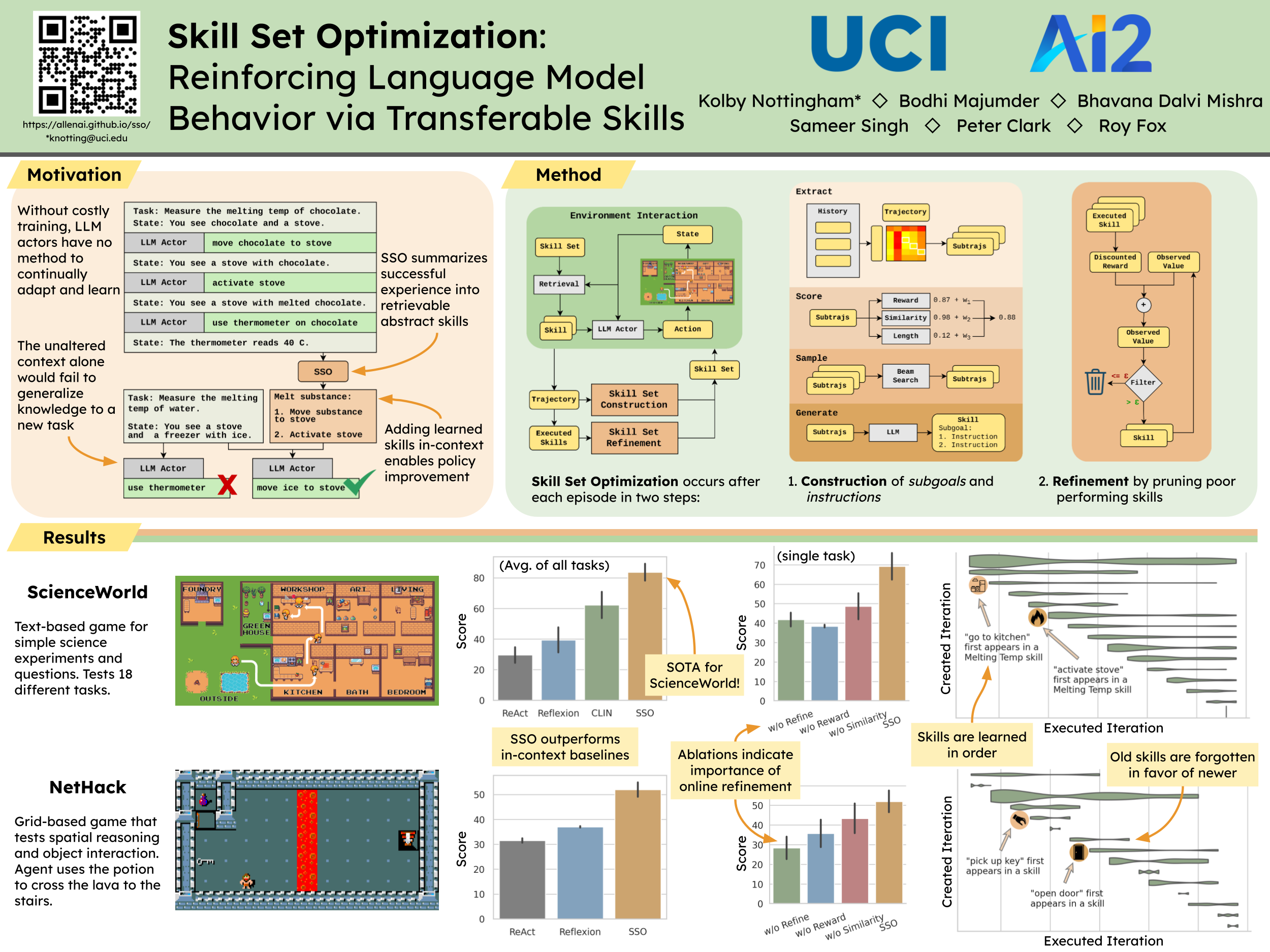
Large language models (LLMs) have recently been used for sequential decision making in interactive environments. However, leveraging environment reward signals for continual LLM actor improvement is not straightforward. We propose Skill Set Optimization (SSO) for improving LLM actor performance through constructing and refining sets of transferable skills. SSO constructs skills by extracting common subtrajectories with high rewards and generating subgoals and instructions to represent each skill. These skills are provided to the LLM actor in-context to reinforce behaviors with high rewards. Then, SSO further refines the skill set by pruning skills that do not continue to result in high rewards. We evaluate our method in the classic videogame NetHack and the text environment ScienceWorld to demonstrate SSO's ability to optimize a set of skills and perform in-context policy improvement. SSO outperforms baselines by 40% in our custom NetHack task and outperforms the previous state-of-the-art in ScienceWorld by 35%.