Improving Generalization in Offline Reinforcement Learning via Adversarial Data Splitting
{kind=link}
Abstract
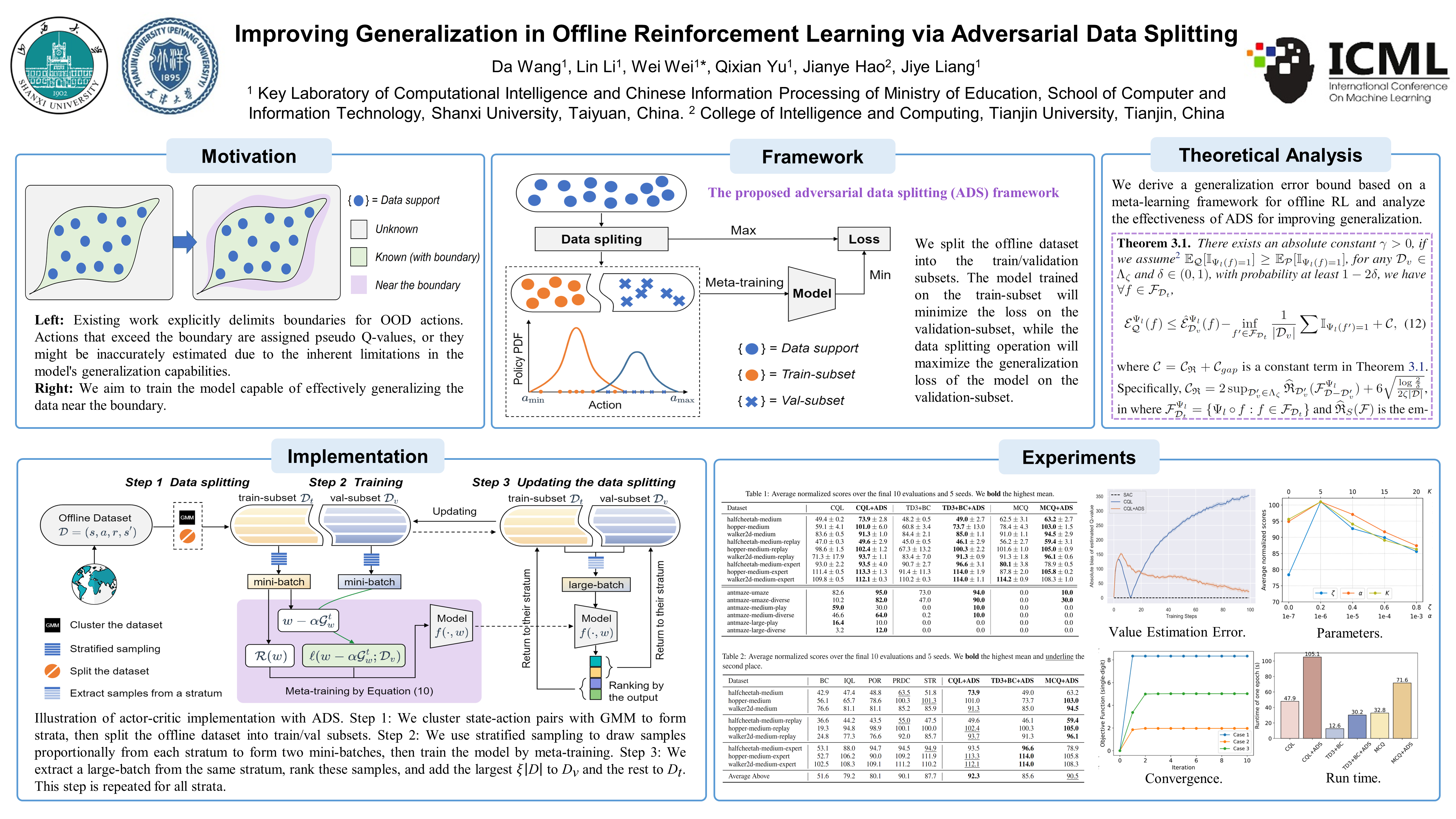
Offline Reinforcement Learning (RL) commonly suffers from the out-of-distribution (OOD) overestimation issue due to the distribution shift. Prior work gradually shifts their focus from suppressing OOD overestimation to avoiding overly conservative learning from suboptimal behavior policies to improve generalization. However, most approaches explicitly delimit boundaries for OOD actions based on the support in the dataset, which can potentially impede the data near these boundaries from acquiring realistic estimates. This paper investigates how to loosen the rigid demarcation of OOD boundaries, adaptively extracting knowledge from empirical data to implicitly improve the model's generalization to nearby unseen data. We introduce an adversarial data splitting (ADS) framework that enforces the model to generalize the distribution shifts simulated from the train/validation subsets splitting of the dataset. Specifically, ADS is modeled as a min-max optimization problem inspired by meta-learning and solved by iterating over the following two steps. First, we train the model on the train-subset to minimize its loss on the validation-subset. Then, we adversarially generate the "hardest" train/validation subsets with the maximum distribution shift, making the model incapable of generalization at that splitting. We derive a generalization error bound for theoretically understanding ADS and verify the effectiveness with extensive experiments. Code is available at https://github.com/DkING-lv6/ADS.