Stochastic Q-learning for Large Discrete Action Spaces
Fares Fourati ⋅ Vaneet Aggarwal ⋅ Mohamed-Slim Alouini
2024 Poster
{kind=link}
Abstract
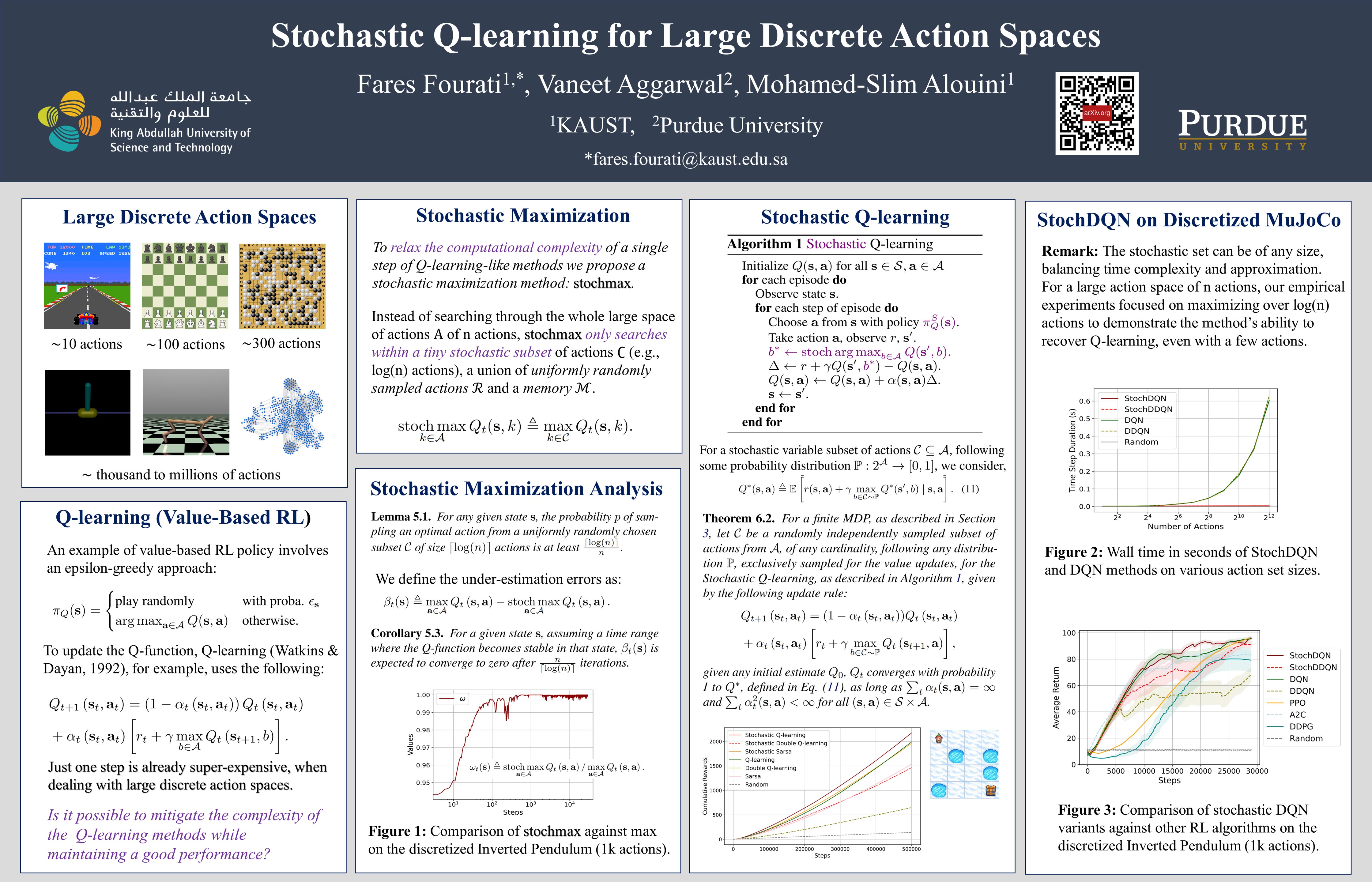
In complex environments with large discrete action spaces, effective decision-making is critical in reinforcement learning (RL). Despite the widespread use of value-based RL approaches like Q-learning, they come with a computational burden, necessitating the maximization of a value function over all actions in each iteration. This burden becomes particularly challenging when addressing large-scale problems and using deep neural networks as function approximators. In this paper, we present stochastic value-based RL approaches which, in each iteration, as opposed to optimizing over the entire set of $n$ actions, only consider a variable stochastic set of a sublinear number of actions, possibly as small as $\mathcal{O}(\log(n))$. The presented stochastic value-based RL methods include, among others, Stochastic Q-learning, StochDQN, and StochDDQN, all of which integrate this stochastic approach for both value-function updates and action selection. The theoretical convergence of Stochastic Q-learning is established, while an analysis of stochastic maximization is provided. Moreover, through empirical validation, we illustrate that the various proposed approaches outperform the baseline methods across diverse environments, including different control problems, achieving near-optimal average returns in significantly reduced time.
Video
Chat is not available.
Successful Page Load