Adversarial Robustness Limits via Scaling-Law and Human-Alignment Studies
Brian Bartoldson ⋅ James Diffenderfer ⋅ Konstantinos Parasyris ⋅ Bhavya Kailkhura
2024 Poster
{kind=link}
Abstract
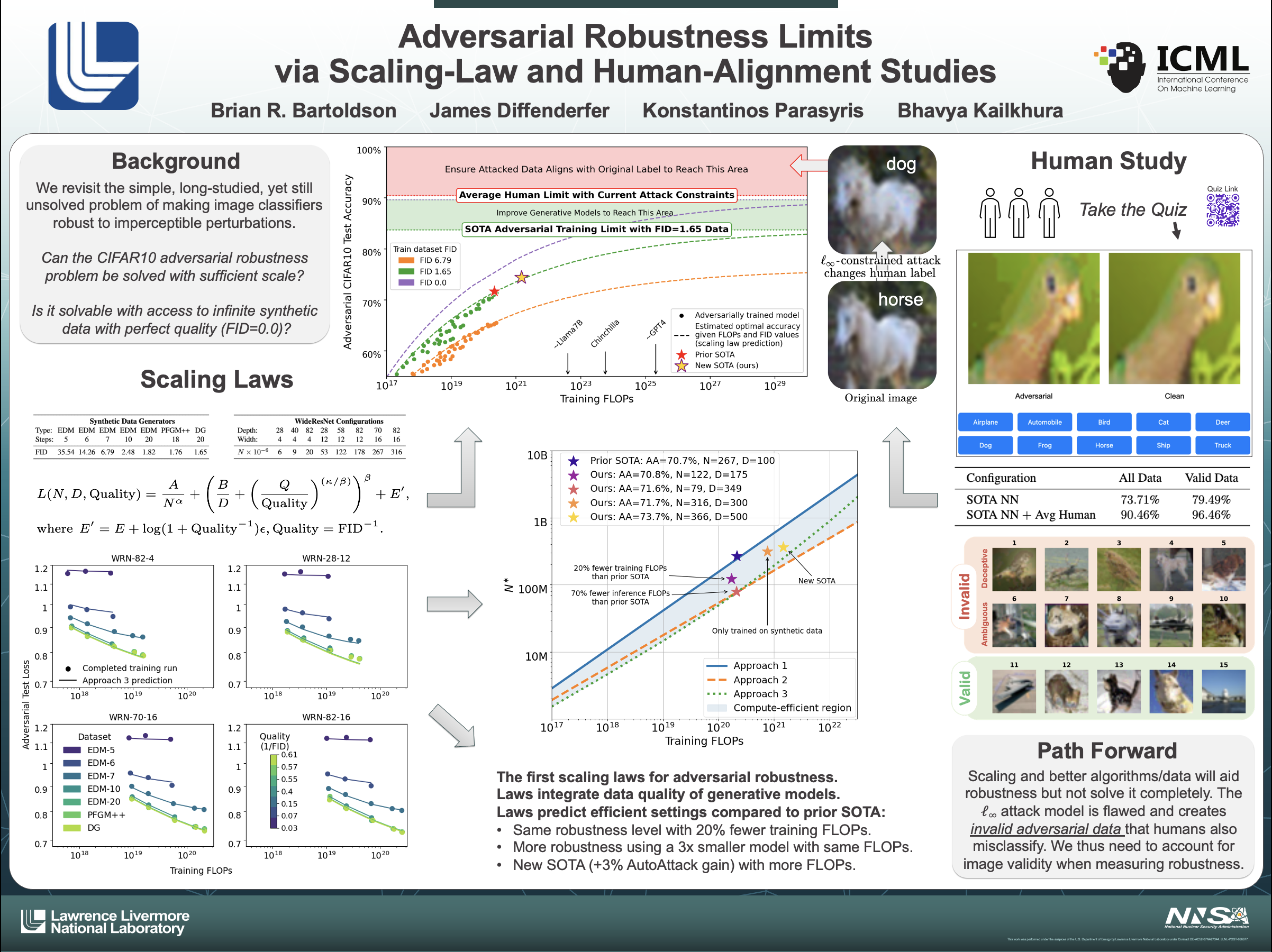
This paper revisits the simple, long-studied, yet still unsolved problem of making image classifiers robust to imperceptible perturbations. Taking CIFAR10 as an example, SOTA clean accuracy is about $100$%, but SOTA robustness to $\ell_{\infty}$-norm bounded perturbations barely exceeds $70$%. To understand this gap, we analyze how model size, dataset size, and synthetic data quality affect robustness by developing the first scaling laws for adversarial training. Our scaling laws reveal inefficiencies in prior art and provide actionable feedback to advance the field. For instance, we discovered that SOTA methods diverge notably from compute-optimal setups, using excess compute for their level of robustness. Leveraging a compute-efficient setup, we surpass the prior SOTA with $20$% ($70$%) fewer training (inference) FLOPs. We trained various compute-efficient models, with our best achieving $74$% AutoAttack accuracy ($+3$% gain). However, our scaling laws also predict robustness slowly grows then plateaus at $90$%: dwarfing our new SOTA by scaling is impractical, and perfect robustness is impossible. To better understand this predicted limit, we carry out a small-scale human evaluation on the AutoAttack data that fools our top-performing model. Concerningly, we estimate that human performance also plateaus near $90$%, which we show to be attributable to $\ell_{\infty}$-constrained attacks' generation of invalid images not consistent with their original labels. Having characterized limiting roadblocks, we outline promising paths for future research.
Video
Chat is not available.
Successful Page Load