Augmenting Decision with Hypothesis in Reinforcement Learning
{kind=link}
Abstract
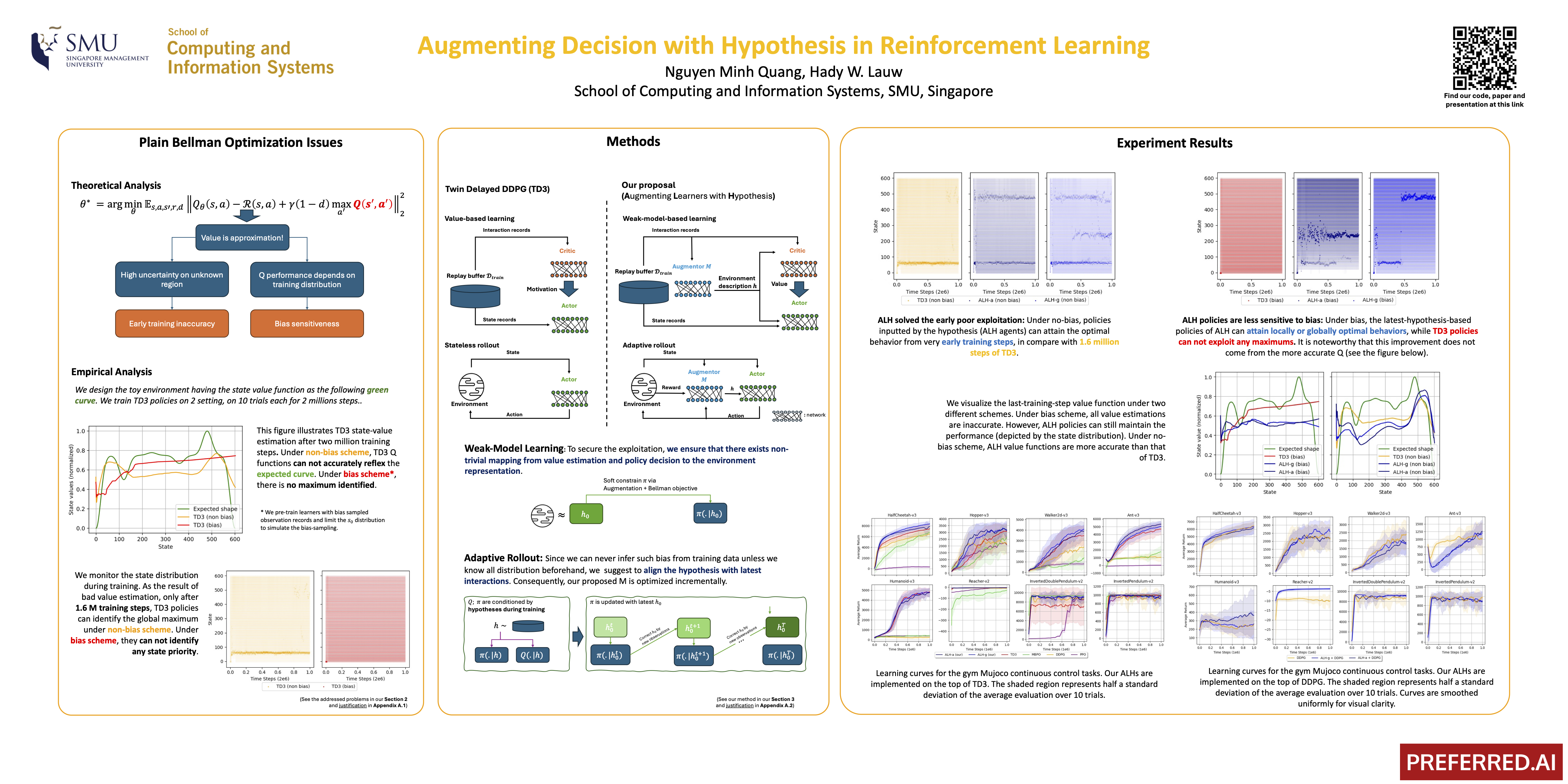
Value-based reinforcement learning is the current State-Of-The-Art due to high sampling efficiency. However, our study shows it suffers from low exploitation in early training period and bias sensitiveness. To address these issues, we propose to augment the decision-making process with hypothesis, a weak form of environment description. Our approach relies on prompting the learning agent with accurate hypotheses, and designing a ready-to-adapt policy through incremental learning. We propose the ALH algorithm, showing detailed analyses on a typical learning scheme and a diverse set of Mujoco benchmarks. Our algorithm produces a significant improvement over value-based learning algorithms and other strong baselines. Our code is available at Github URL.