Efficient Exploration for LLMs
Vikranth Dwaracherla ⋅ Seyed Mohammad Asghari ⋅ Botao Hao ⋅ Benjamin Van Roy
2024 Poster
{kind=link}
Abstract
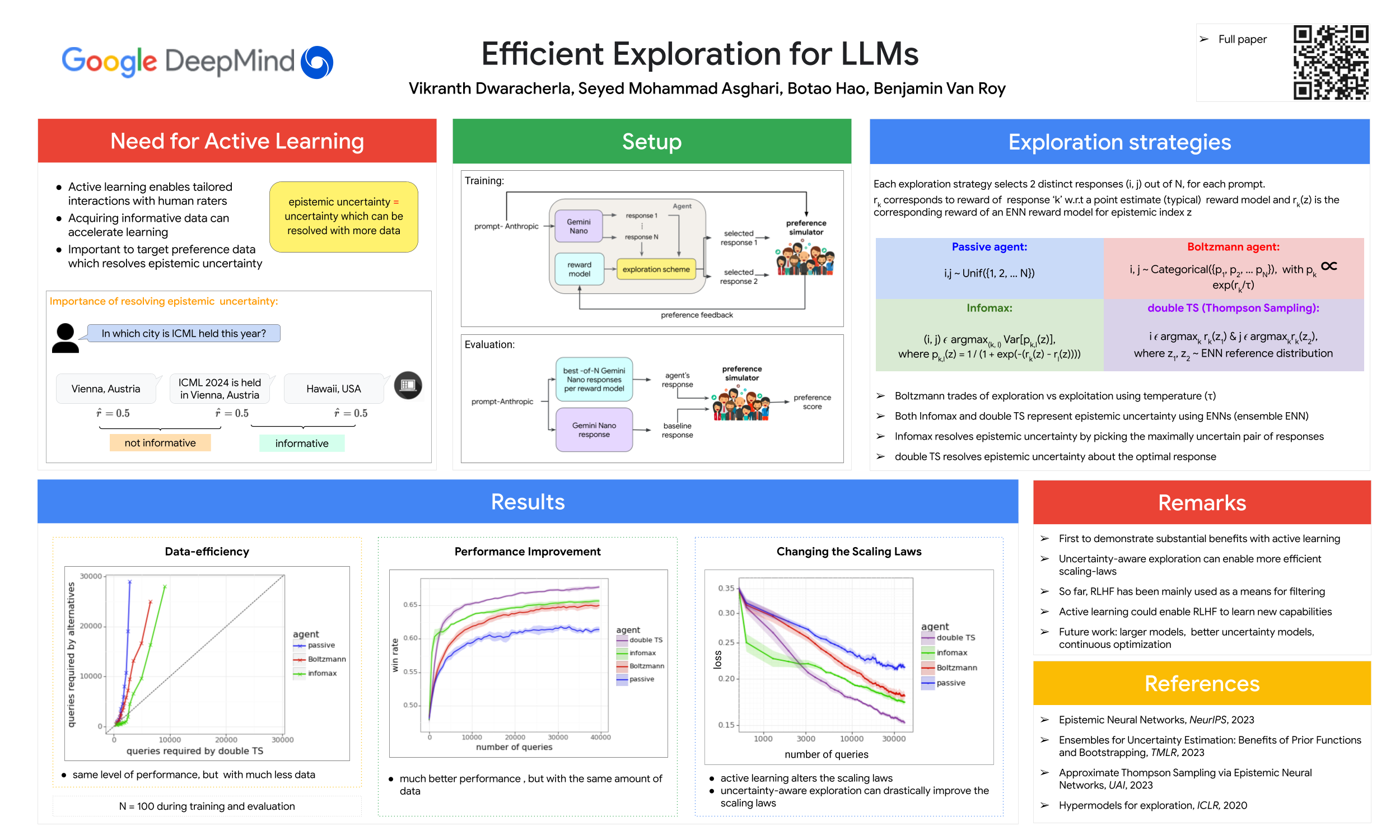
We present evidence of substantial benefit from efficient exploration in gathering human feedback to improve large language models. In our experiments, an agent sequentially generates queries while fitting a reward model to the feedback received. Our best-performing agent generates queries using double Thompson sampling, with uncertainty represented by an epistemic neural network. Our results demonstrate that efficient exploration enables high levels of performance with far fewer queries. Further, both uncertainty estimation and the choice of exploration scheme play critical roles.
Chat is not available.
Successful Page Load