Why Larger Language Models Do In-context Learning Differently?
{kind=link}
Abstract
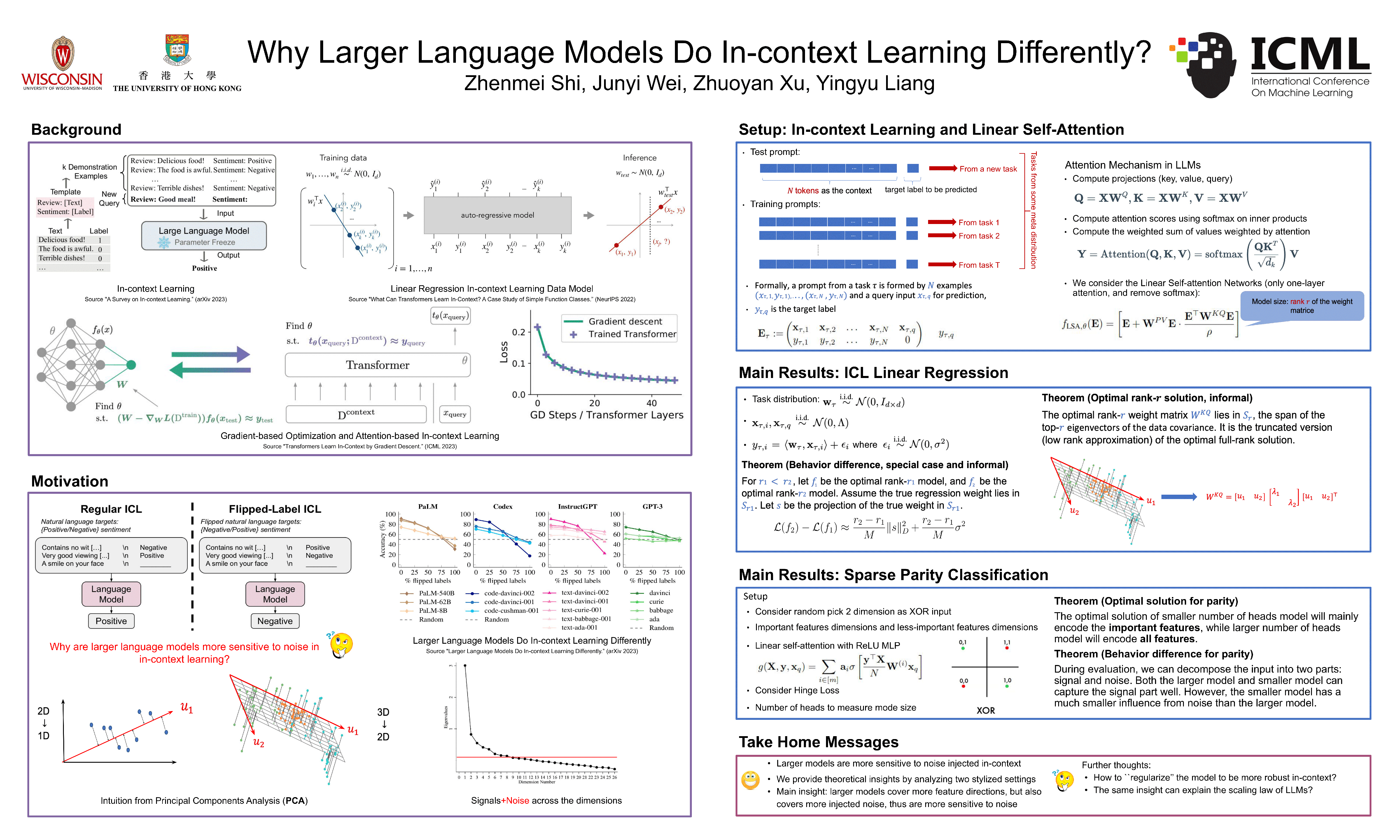
Large language models (LLM) have emerged as a powerful tool for AI, with the key ability of in-context learning (ICL), where they can perform well on unseen tasks based on a brief series of task examples without necessitating any adjustments to the model parameters. One recent interesting mysterious observation is that models of different scales may have different ICL behaviors: larger models tend to be more sensitive to noise in the test context. This work studies this observation theoretically aiming to improve the understanding of LLM and ICL. We analyze two stylized settings: (1) linear regression with one-layer single-head linear transformers and (2) parity classification with two-layer multiple attention heads transformers (non-linear data and non-linear model). In both settings, we give closed-form optimal solutions and find that smaller models emphasize important hidden features while larger ones cover more hidden features; thus, smaller models are more robust to noise while larger ones are more easily distracted, leading to different ICL behaviors. This sheds light on where transformers pay attention to and how that affects ICL. Preliminary experimental results on large base and chat models provide positive support for our analysis.