GeoReasoner: Geo-localization with Reasoning in Street Views using a Large Vision-Language Model
{kind=link}
Abstract
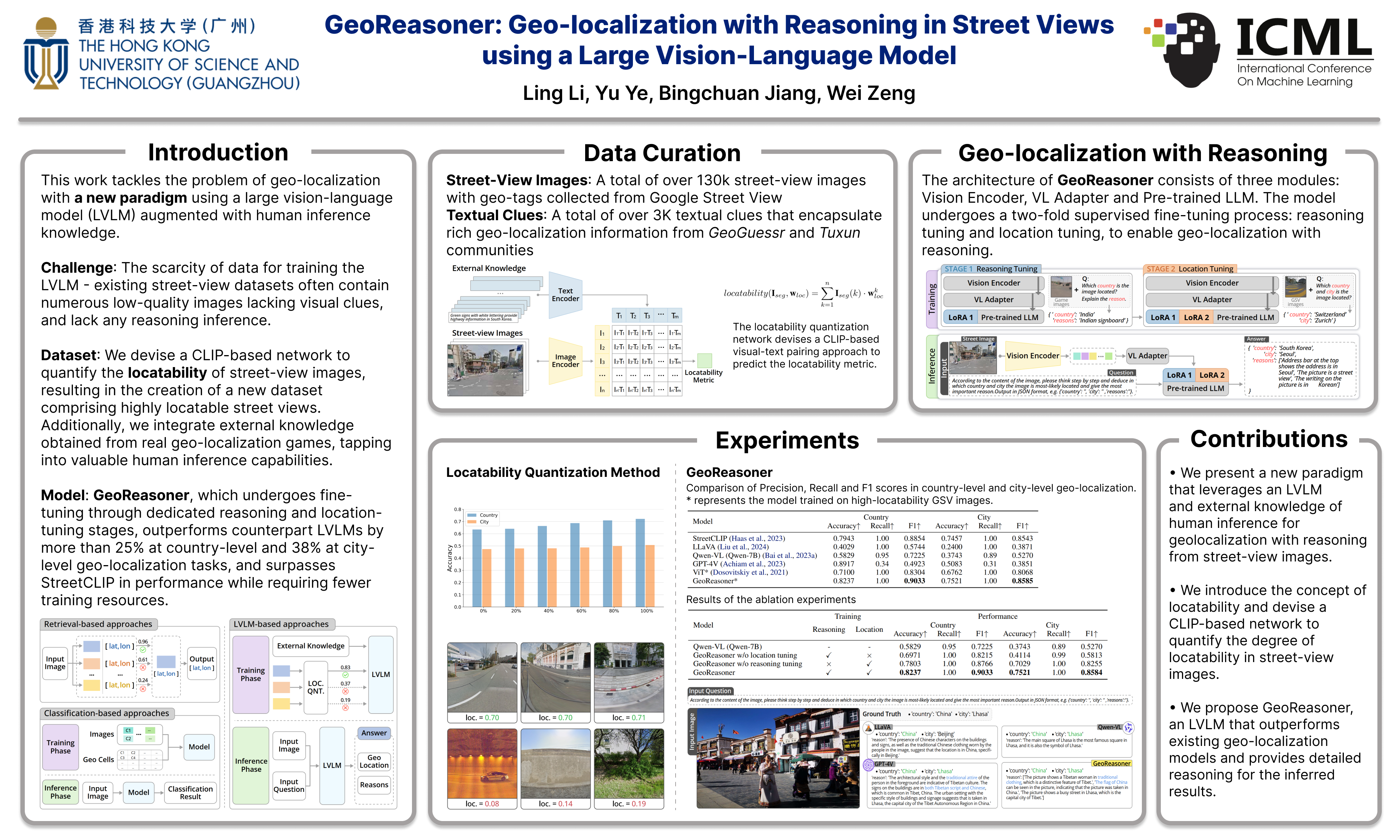
This work tackles the problem of geo-localization with a new paradigm using a large vision-language model (LVLM) augmented with human inference knowledge. A primary challenge here is the scarcity of data for training the LVLM - existing street-view datasets often contain numerous low-quality images lacking visual clues, and lack any reasoning inference. To address the data-quality issue, we devise a CLIP-based network to quantify the degree of street-view images being locatable, leading to the creation of a new dataset comprising highly locatable street views. To enhance reasoning inference, we integrate external knowledge obtained from real geo-localization games, tapping into valuable human inference capabilities. The data are utilized to train GeoReasoner, which undergoes fine-tuning through dedicated reasoning and location-tuning stages. Qualitative and quantitative evaluations illustrate that GeoReasoner outperforms counterpart LVLMs by more than 25% at country-level and 38% at city-level geo-localization tasks, and surpasses StreetCLIP performance while requiring fewer training resources. The data and code are available at https://github.com/lingli1996/GeoReasoner.