FedREDefense: Defending against Model Poisoning Attacks for Federated Learning using Model Update Reconstruction Error
{kind=link}
Abstract
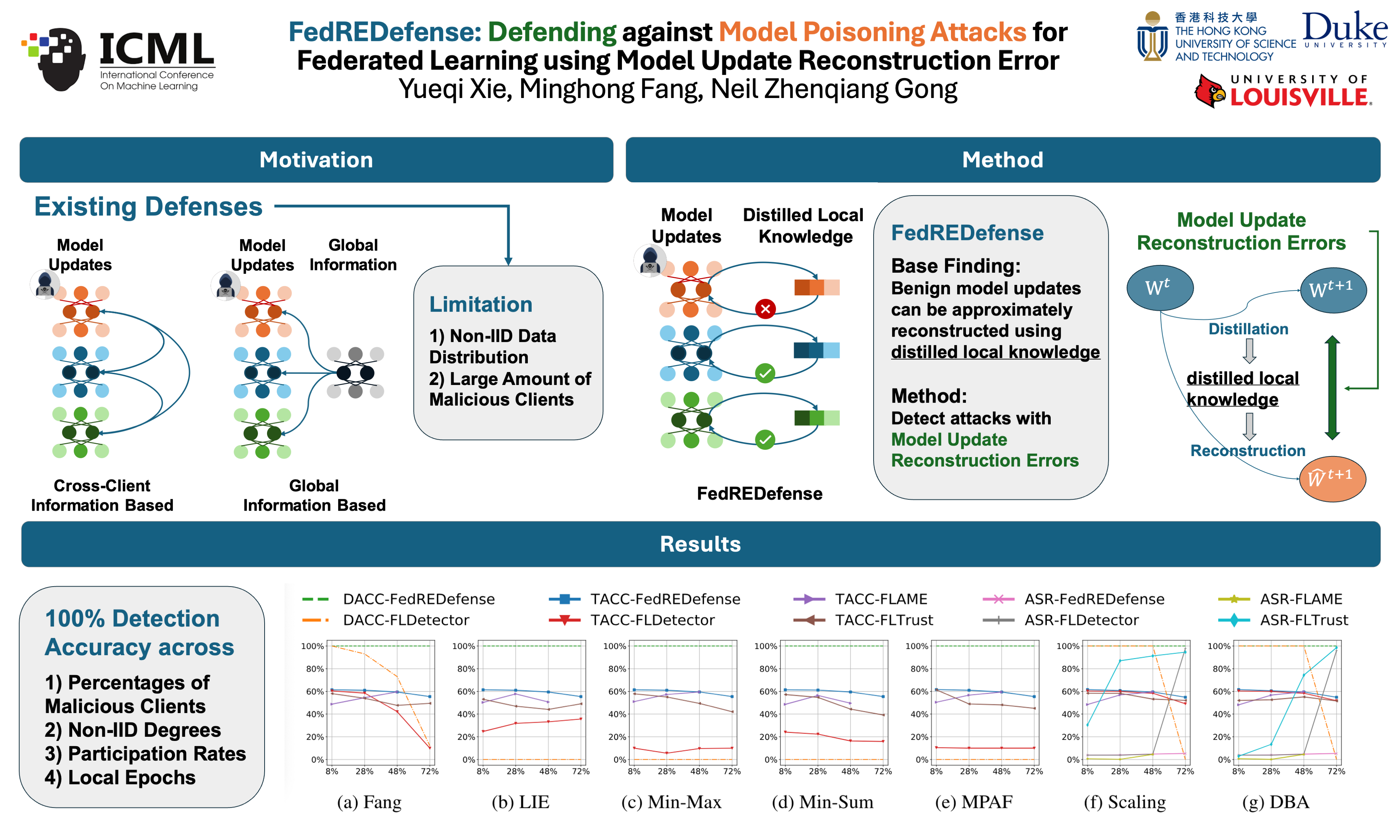
Federated Learning (FL) faces threats from model poisoning attacks. Existing defenses, typically relying on cross-client/global information to mitigate these attacks, fall short when faced with non-IID data distributions and/or a large number of malicious clients. To address these challenges, we present FedREDefense. Unlike existing methods, it doesn't hinge on similar distributions across clients or a predominant presence of benign clients. Instead, it assesses the likelihood that a client's model update is a product of genuine training, solely based on the characteristics of the model update itself. Our key finding is that model updates stemming from genuine training can be approximately reconstructed with some distilled local knowledge, while those from deliberate handcrafted model poisoning attacks cannot. Drawing on this distinction, FedREDefense identifies and filters out malicious clients based on the discrepancies in their model update Reconstruction Errors. Empirical tests on three benchmark datasets confirm that FedREDefense successfully filters model poisoning attacks in FL—even in scenarios with high non-IID degrees and large numbers of malicious clients.