SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
{kind=link}
Abstract
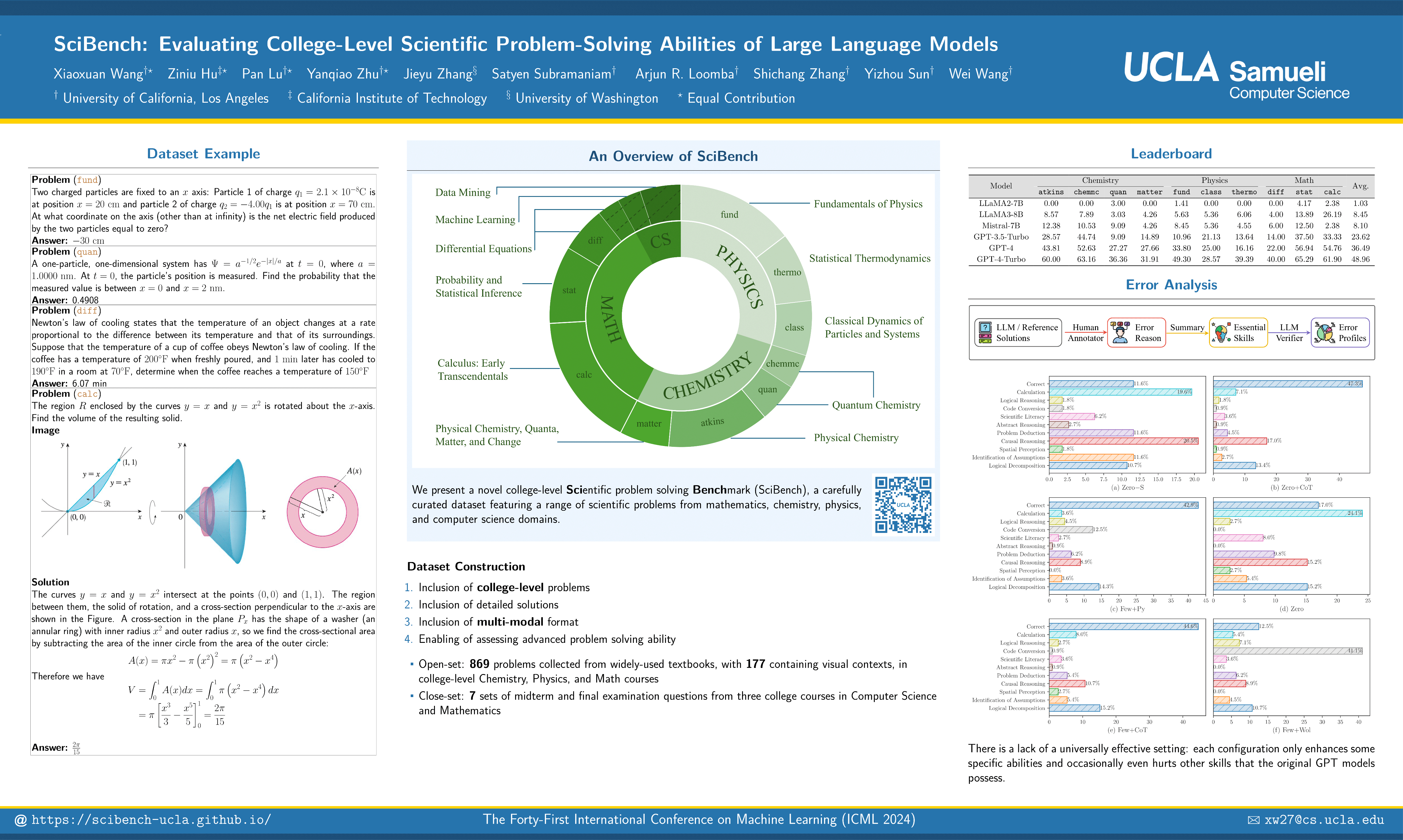
Most existing Large Language Model (LLM) benchmarks on scientific problem reasoning focus on problems grounded in high-school subjects and are confined to elementary algebraic operations. To systematically examine the reasoning capabilities required for solving complex scientific problems, we introduce an expansive benchmark suite SciBench for LLMs. SciBench contains a carefully curated dataset featuring a range of collegiate-level scientific problems from mathematics, chemistry, and physics domains. Based on the dataset, we conduct an in-depth benchmarking study of representative open-source and proprietary LLMs with various prompting strategies. The results reveal that current LLMs fall short of delivering satisfactory performance, with the best overall score of merely 43.22%. Furthermore, through a detailed user study, we categorize the errors made by LLMs into ten problem-solving abilities. Our analysis indicates that no single prompting strategy significantly outperforms the others and some strategies that demonstrate improvements in certain problem-solving skills could result in declines in other skills. We envision that SciBench will catalyze further developments in the reasoning abilities of LLMs, thereby ultimately contributing to scientific research and discovery.