Understanding the Impact of Introducing Constraints at Inference Time on Generalization Error
{kind=link}
Abstract
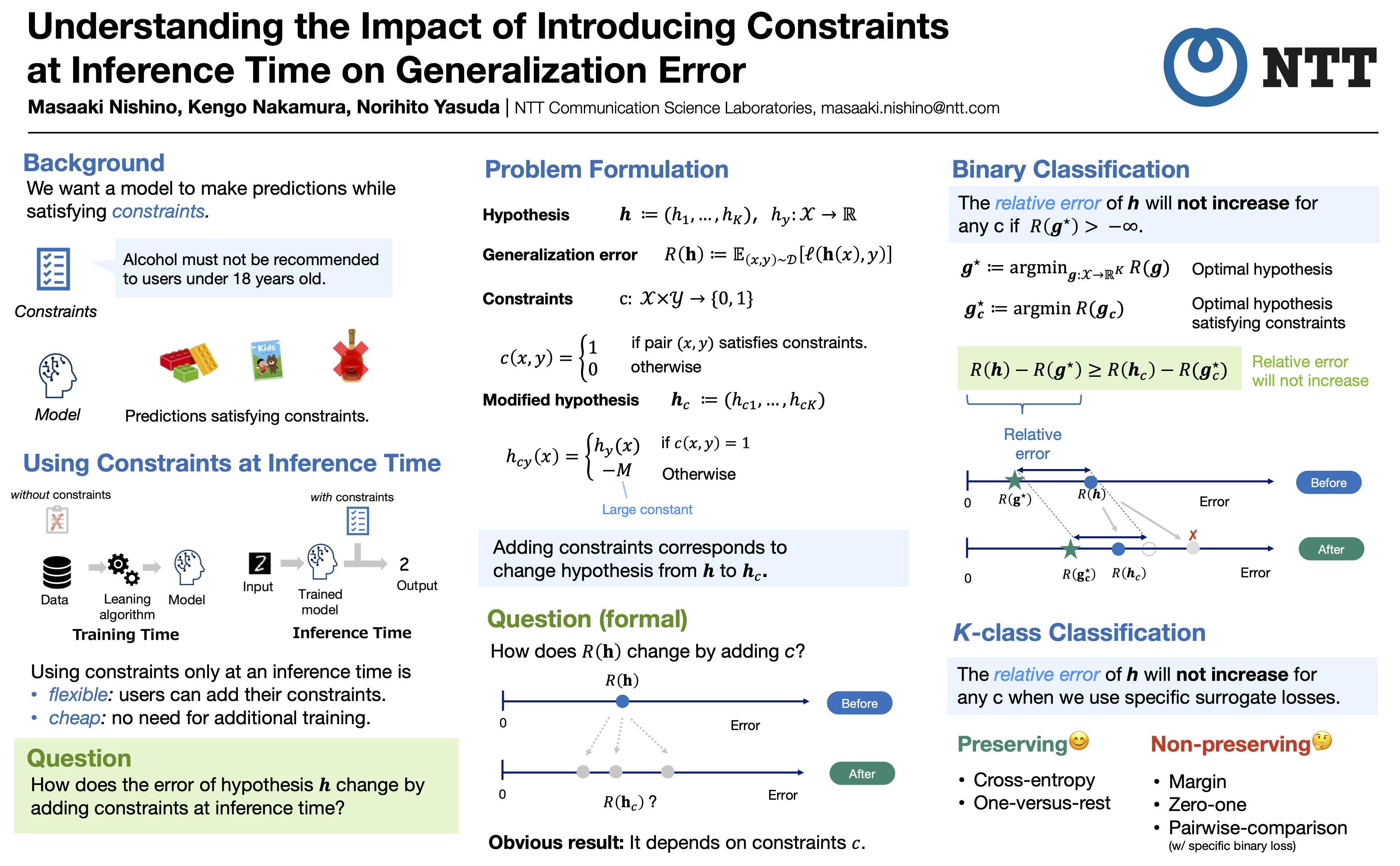
Since machine learning technologies are being used in various practical situations, models with merely low prediction errors might not be satisfactory; prediction errors occurring with a low probability might yield dangerous results in some applications. Therefore, there are attempts to achieve an ML model whose input-output pairs are guaranteed to satisfy given constraints. Among such attempts, many previous works chose the approach of modifying the outputs of an ML model at the inference time to satisfy the constraints. Such a strategy is handy because we can control its output without expensive training or fine-tuning. However, it is unclear whether using constraints only in the inference time degrades a model's predictive performance. This paper analyses how the generalization error bounds change when we only put constraints in the inference time. Our main finding is that a class of loss functions preserves the relative generalization error, i.e., the difference in generalization error compared with the best model will not increase by imposing constraints at the inference time on multi-class classification. Some popular loss functions preserve the relative error, including the softmax cross-entropy loss. On the other hand, we also show that some loss functions do not preserve relative error when we use constraints. Our results suggest the importance of choosing a suitable loss function when we only use constraints in the inference time.