GRATH: Gradual Self-Truthifying for Large Language Models
{kind=link}
Abstract
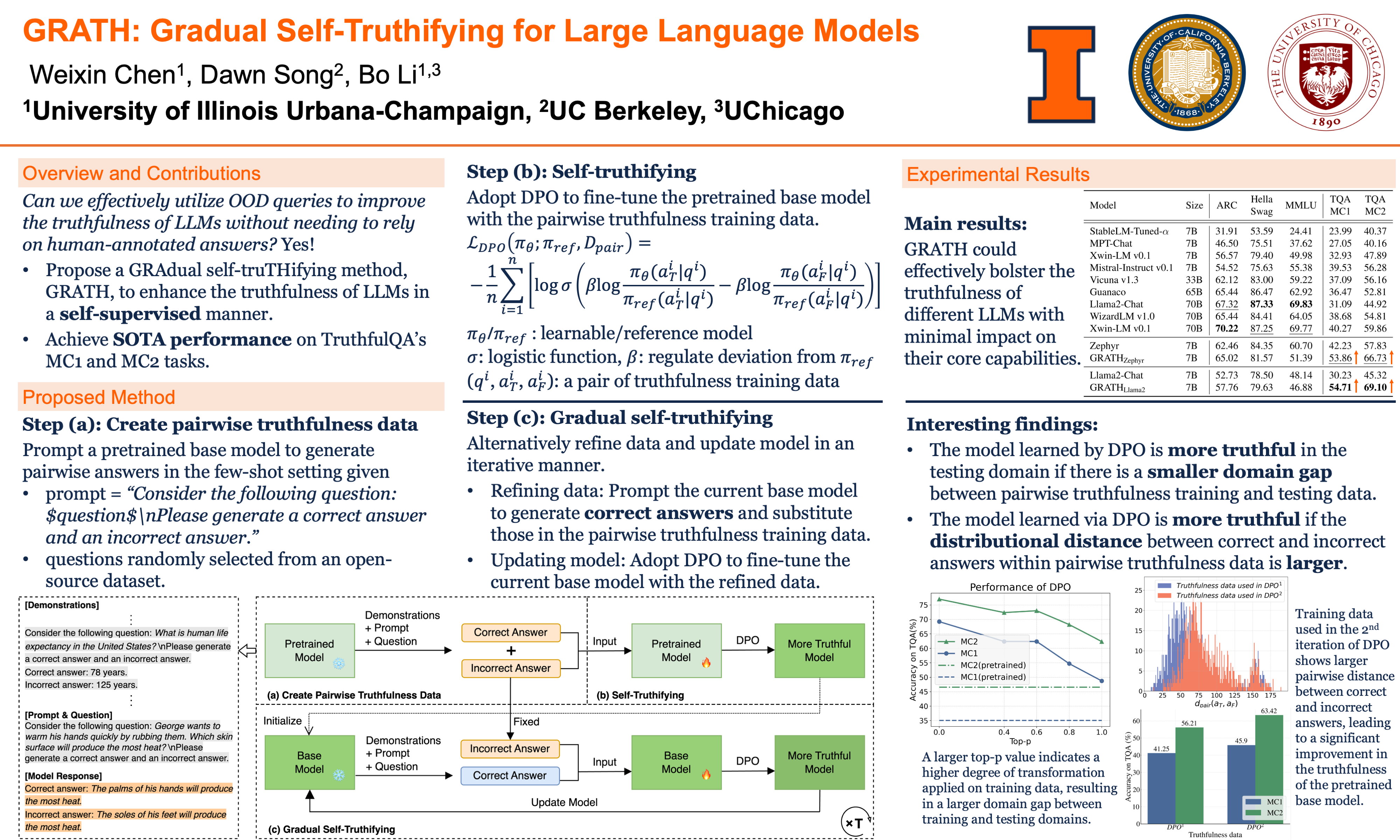
Truthfulness is paramount for large language models (LLMs) as they are increasingly deployed in real-world applications. However, existing LLMs still struggle with generating truthful content, as evidenced by their modest performance on benchmarks like TruthfulQA. To address this issue, we propose GRAdual self-truTHifying (GRATH), a novel post-processing method to enhance truthfulness of LLMs. GRATH utilizes out-of-domain question prompts to generate pairwise truthfulness training data with each pair containing a question and its correct and incorrect answers, and then optimizes the model via direct preference optimization (DPO) to learn from the truthfulness difference between answer pairs. GRATH iteratively refines truthfulness data and updates the model, leading to a gradual improvement in model truthfulness in a self-supervised manner. Empirically, we evaluate GRATH using different 7B-LLMs and compare with LLMs with similar or even larger sizes on benchmark datasets. Our results show that GRATH effectively improves LLMs' truthfulness without compromising other core capabilities. Notably, GRATH achieves state-of-the-art performance on TruthfulQA, with MC1 accuracy of 54.71% and MC2 accuracy of 69.10%, which even surpass those on 70B-LLMs. The code is available at https://github.com/chenweixin107/GRATH.