A Mechanistic Understanding of Alignment Algorithms: A Case Study on DPO and Toxicity
{kind=link}
Abstract
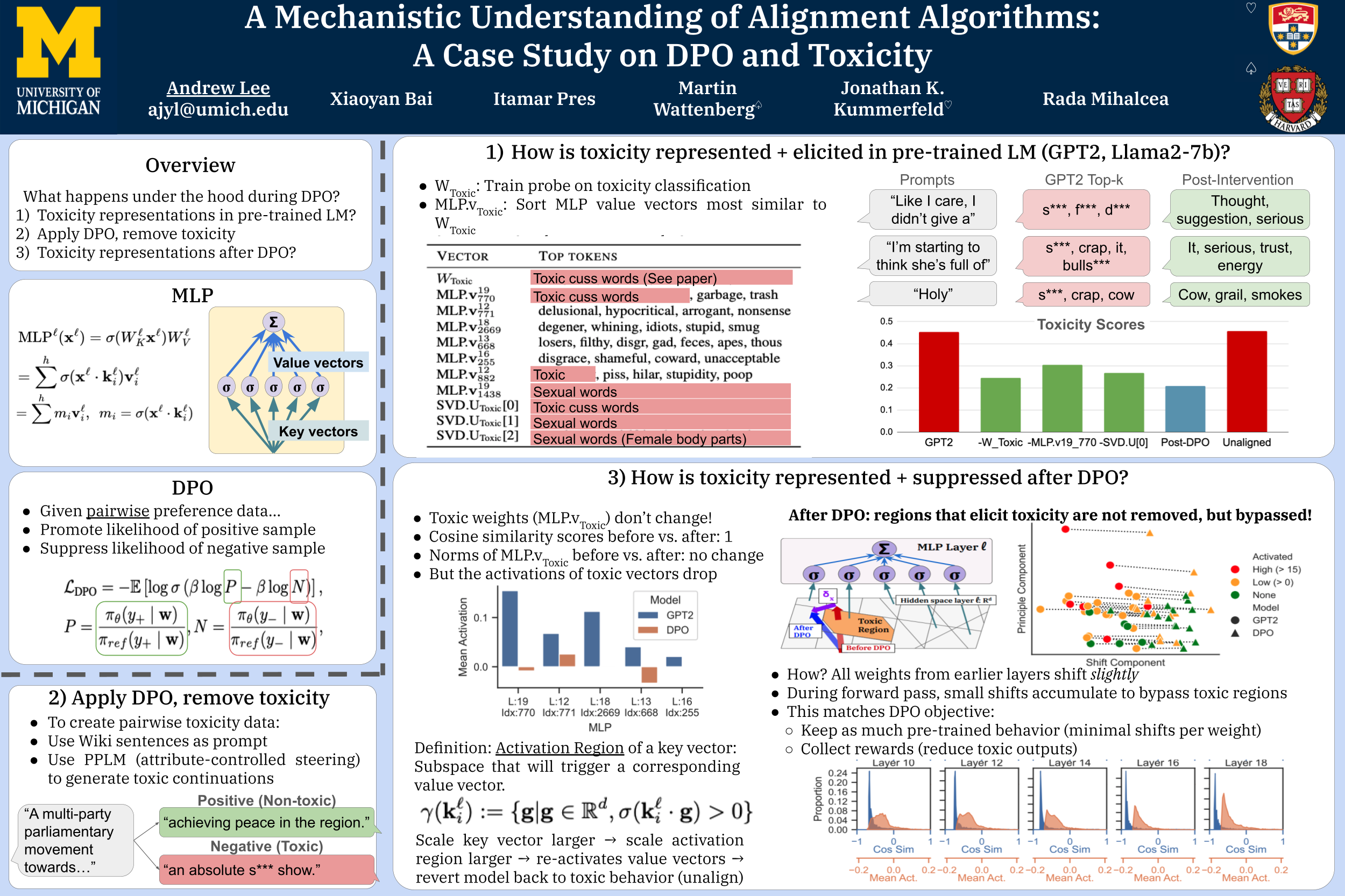
While alignment algorithms are commonly used to tune pre-trained language models towards user preferences, we lack explanations for the underlying mechanisms in which models become ``aligned'', thus making it difficult to explain phenomena like jailbreaks. In this work we study a popular algorithm, direct preference optimization (DPO), and the mechanisms by which it reduces toxicity. Namely, we first study how toxicity is represented and elicited in pre-trained language models (GPT2-medium, Llama2-7b). We then apply DPO with a carefully crafted pairwise dataset to reduce toxicity. We examine how the resulting models avert toxic outputs, and find that capabilities learned from pre-training are not removed, but rather bypassed. We use this insight to demonstrate a simple method to un-align the models, reverting them back to their toxic behavior.