OLLIE: Imitation Learning from Offline Pretraining to Online Finetuning
{kind=link}
Abstract
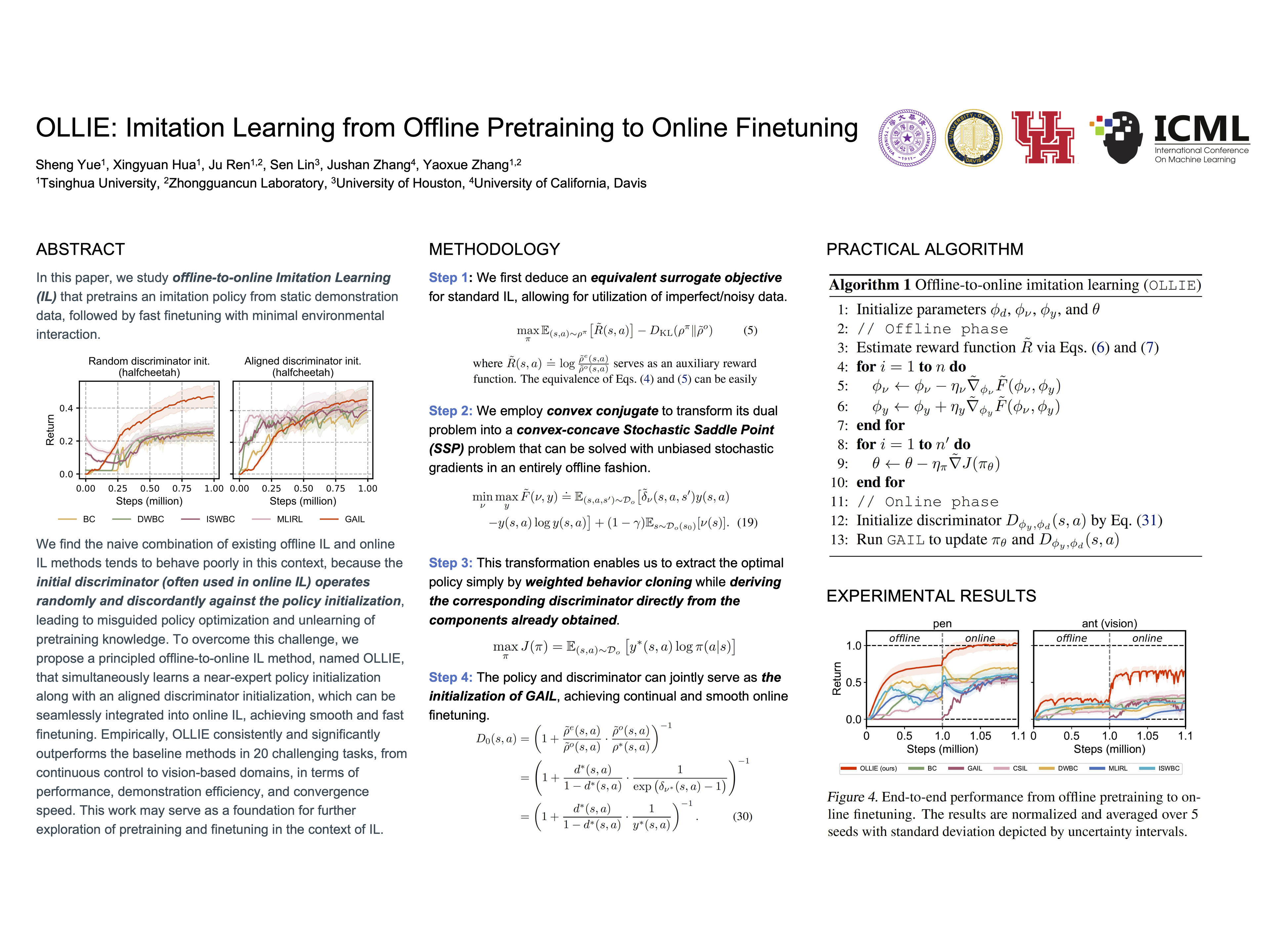
In this paper, we study offline-to-online Imitation Learning (IL) that pretrains an imitation policy from static demonstration data, followed by fast finetuning with minimal environmental interaction. We find the naive combination of existing offline IL and online IL methods tends to behave poorly in this context, because the initial discriminator (often used in online IL) operates randomly and discordantly against the policy initialization, leading to misguided policy optimization and unlearning of pretraining knowledge. To overcome this challenge, we propose a principled offline-to-online IL method, named OLLIE, that simultaneously learns a near-expert policy initialization along with an aligned discriminator initialization, which can be seamlessly integrated into online IL, achieving smooth and fast finetuning. Empirically, OLLIE consistently and significantly outperforms the baseline methods in 20 challenging tasks, from continuous control to vision-based domains, in terms of performance, demonstration efficiency, and convergence speed. This work may serve as a foundation for further exploration of pretraining and finetuning in the context of IL.