Dense Reward for Free in Reinforcement Learning from Human Feedback
{kind=link}
Abstract
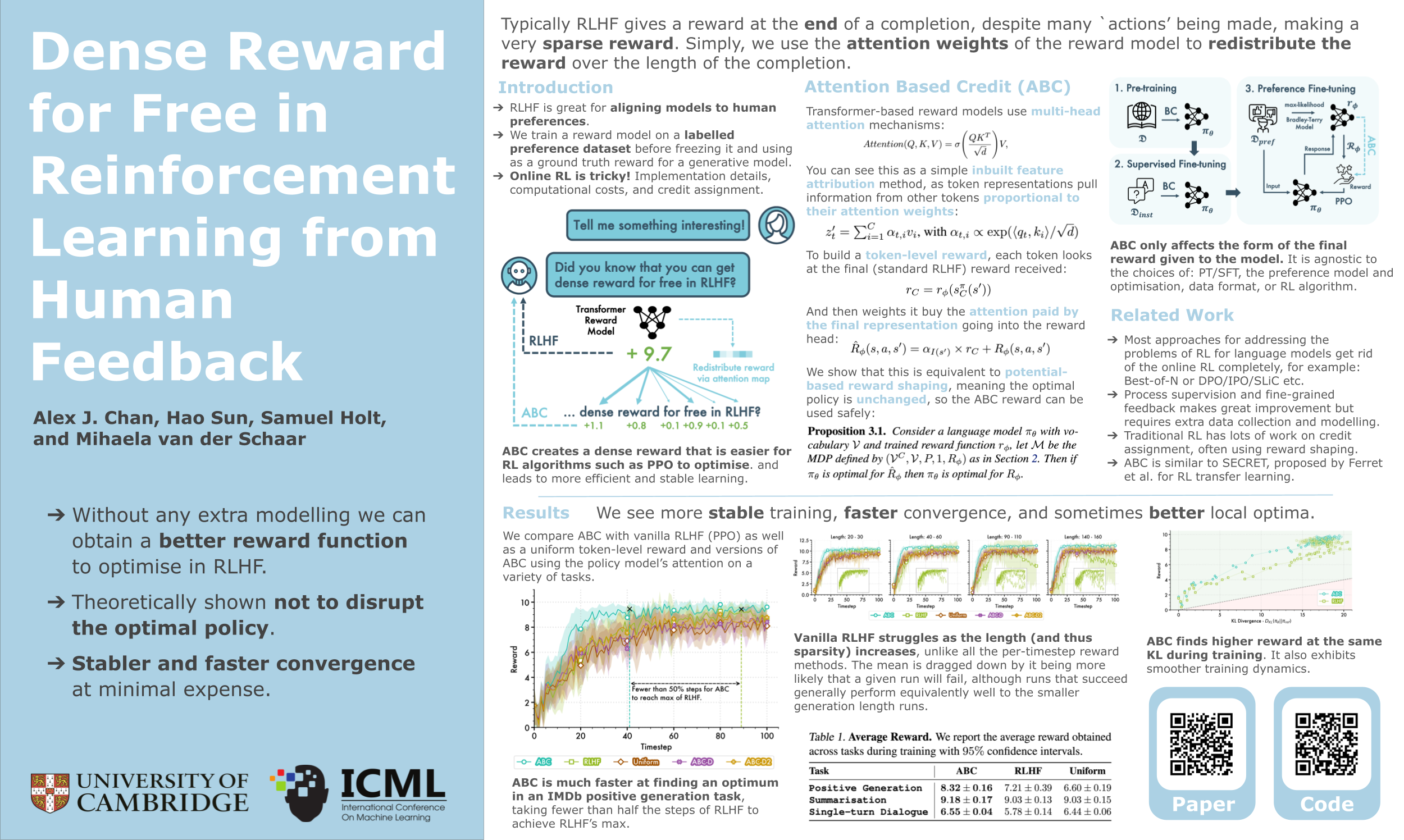
Reinforcement Learning from Human Feedback (RLHF) has been credited as the key advance that has allowed Large Language Models (LLMs) to effectively follow instructions and produce useful assistance. Classically, this involves generating completions from the LLM in response to a query before using a separate reward model to assign a score to the full completion. As an auto-regressive process, the LLM has to take many “actions” (selecting individual tokens) and only receives a single, sparse reward at the end of an episode, a setup that is known to be difficult to optimise in traditional reinforcement learning. In this work we leverage the fact that the reward model contains more information than just its scalar output, in particular, it calculates an attention map over tokens as part of the transformer architecture. We use these attention weights to redistribute the reward along the whole completion, effectively densifying the signal and highlighting the most important tokens, all without incurring extra computational cost or requiring any additional modelling. We demonstrate that, theoretically, this approach is equivalent to potential-based reward shaping, ensuring that the optimal policy remains unchanged. Empirically, we show that it stabilises training, accelerates the rate of learning, and, in practical cases, may lead to better local optima.