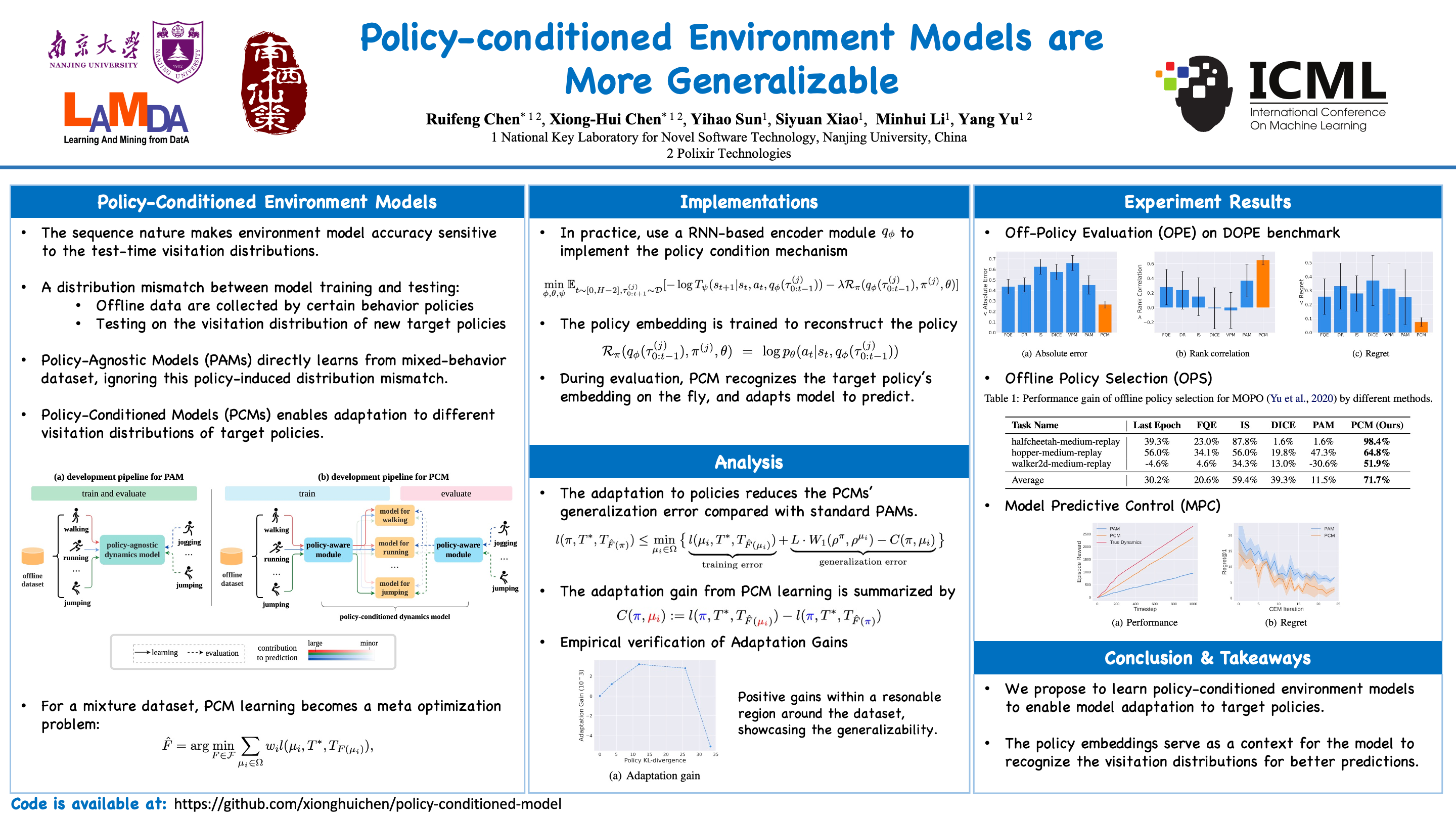
Policy-conditioned Environment Models are More Generalizable
{kind=link}
Abstract
In reinforcement learning, it is crucial to have an accurate environment dynamics model to evaluate different policies' value in downstream tasks like offline policy optimization and policy evaluation. However, the learned model is known to be inaccurate in predictions when evaluating target policies different from data-collection policies. In this work, we found that utilizing policy representation for model learning, called policy-conditioned model (PCM) learning, is useful to mitigate the problem, especially when the offline dataset is collected from diversified behavior policies. The reason beyond that is in this case, PCM becomes a meta-dynamics model that is trained to be aware of and focus on the evaluation policies that on-the-fly adjust the model to be suitable to the evaluation policies’ state-action distribution, thus improving the prediction accuracy. Based on that intuition, we propose an easy-to-implement yet effective algorithm of PCM for accurate model learning. We also give a theoretical analysis and experimental evidence to demonstrate the feasibility of reducing value gaps by adapting the dynamics model under different policies. Experiment results show that PCM outperforms the existing SOTA off-policy evaluation methods in the DOPE benchmark by a large margin, and derives significantly better policies in offline policy selection and model predictive control compared with the standard model learning method.