Bayesian Knowledge Distillation: A Bayesian Perspective of Distillation with Uncertainty Quantification
{kind=link}
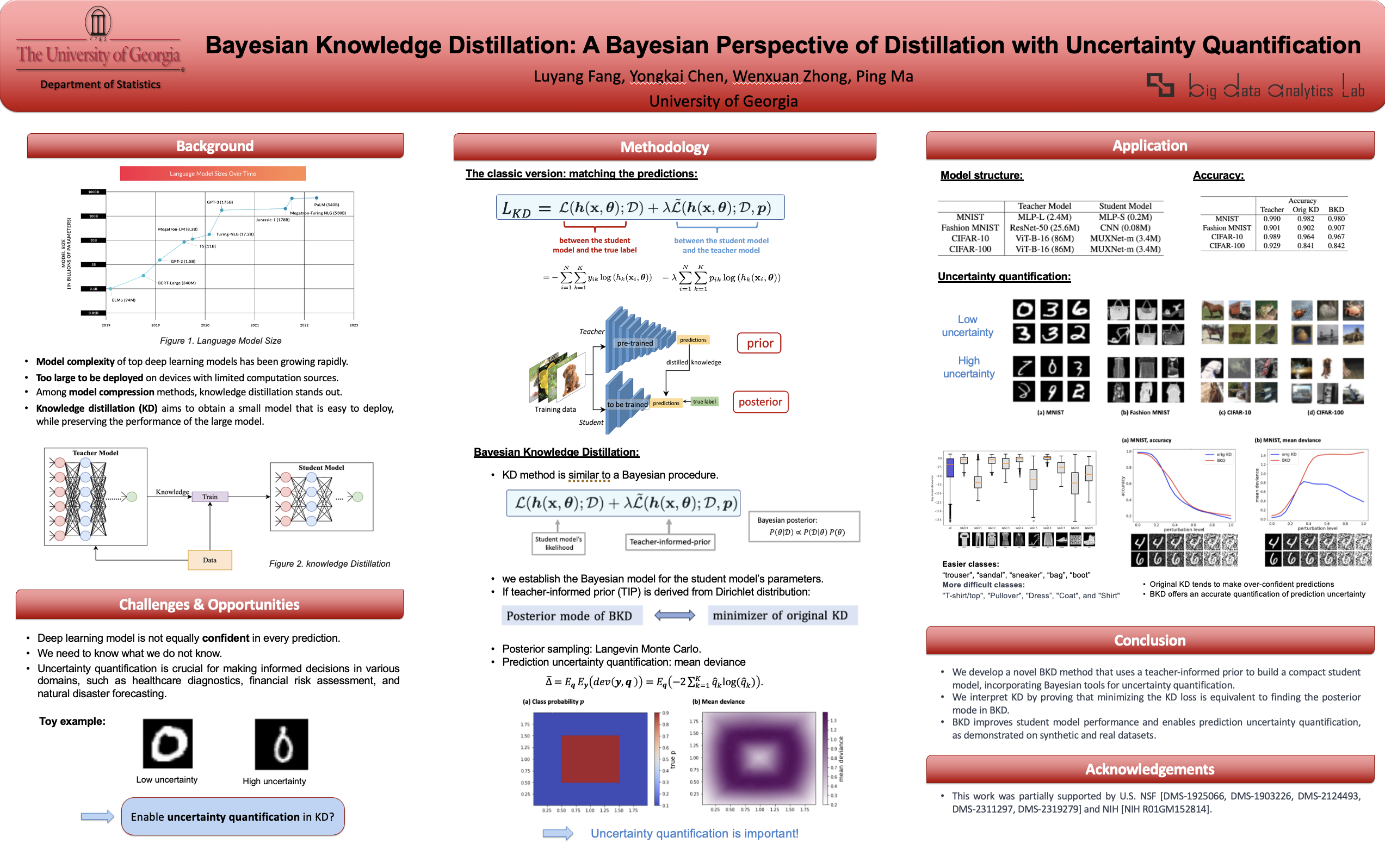
Abstract
Knowledge distillation (KD) has been widely used for model compression and deployment acceleration. Nonetheless, the statistical insight of the remarkable performance of KD remains elusive, and methods for evaluating the uncertainty of the distilled model/student model are lacking. To address these issues, we establish a close connection between KD and a Bayesian model. In particular, we develop an innovative method named Bayesian Knowledge Distillation (BKD) to provide a transparent interpretation of the working mechanism of KD, and a suite of Bayesian inference tools for the uncertainty quantification of the student model. In BKD, the regularization imposed by the teacher model in KD is formulated as a teacher-informed prior for the student model's parameters. Consequently, we establish the equivalence between minimizing the KD loss and estimating the posterior mode in BKD. Efficient Bayesian inference algorithms are developed based on the stochastic gradient Langevin Monte Carlo and examined with extensive experiments on uncertainty ranking and credible intervals construction for predicted class probabilities.