Degeneration-free Policy Optimization: RL Fine-Tuning for Language Models without Degeneration
{kind=link}
Abstract
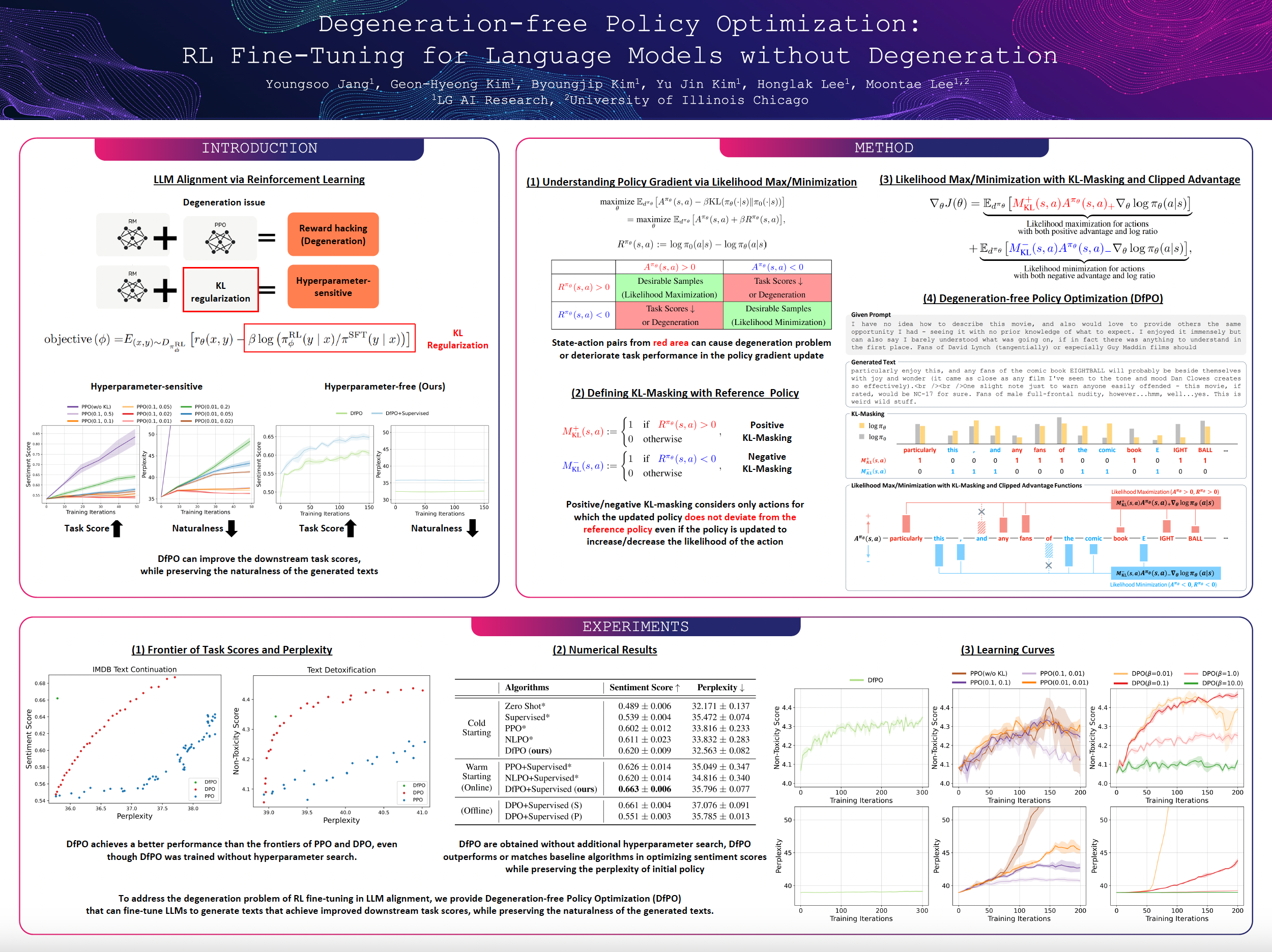
As the pre-training objectives (e.g., next token prediction) of language models (LMs) are inherently not aligned with task scores, optimizing LMs to achieve higher downstream task scores is essential. One of the promising approaches is to fine-tune LMs through reinforcement learning (RL). However, conventional RL methods based on PPO and a penalty of KL divergence are vulnerable to text degeneration where LMs do not generate natural texts anymore after RL fine-tuning. To address this problem, we provide Degeneration-free Policy Optimization (DfPO) that can fine-tune LMs to generate texts that achieve improved downstream task scores, while preserving the ability to generate natural texts. To achieve this, we introduce KL-masking which masks out the actions that potentially cause deviation from the reference policy when its likelihood is increased or decreased. Then, we devise truncated advantage functions for separately performing likelihood maximization and minimization to improve the task performance. In the experiments, we provide the results of DfPO and baseline algorithms on various generative NLP tasks including text continuation, text detoxification, and commonsense generation. Our experiments demonstrate that DfPO successfully improves the downstream task scores while preserving the ability to generate natural texts, without requiring additional hyperparameter search.