Low-Rank Similarity Mining for Multimodal Dataset Distillation
{kind=link}
Abstract
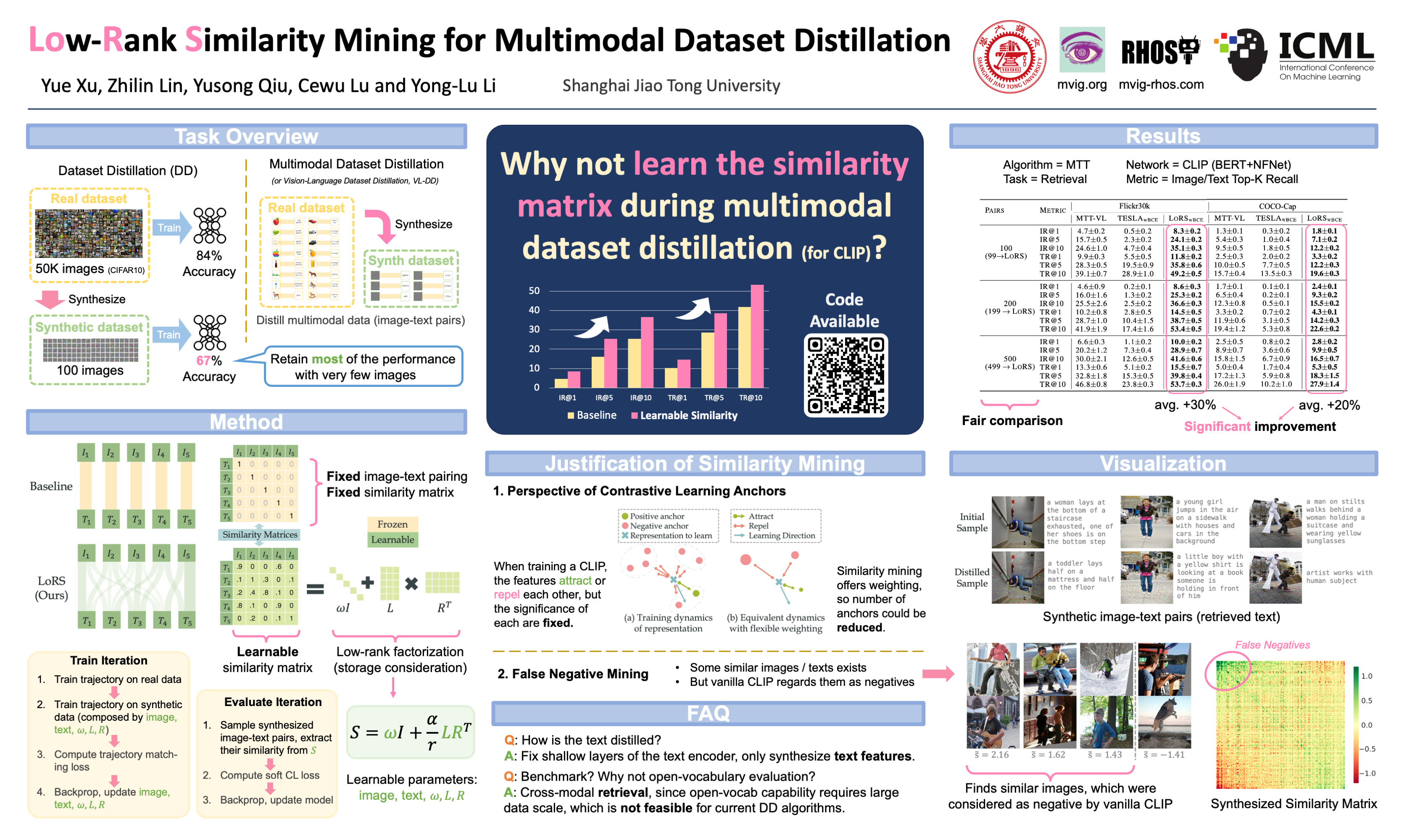
Though dataset distillation has witnessed rapid development in recent years, the distillation of multimodal data, e.g., image-text pairs, poses unique and under-explored challenges. Unlike unimodal data, image-text contrastive learning (ITC) data lack inherent categorization and should instead place greater emphasis on modality correspondence. In this work, we propose Low-Rank Similarity Mining (LoRS) for multimodal dataset distillation, that concurrently distills a ground truth similarity matrix with image-text pairs, and leverages low-rank factorization for efficiency and scalability. The proposed approach brings significant improvement to the existing algorithms, marking a significant contribution to the field of visual-language dataset distillation. We advocate adopting LoRS as a foundational synthetic data setup for image-text dataset distillation. Our code is available at https://github.com/silicx/LoRS_Distill.