STEER: Assessing the Economic Rationality of Large Language Models
{kind=link}
Abstract
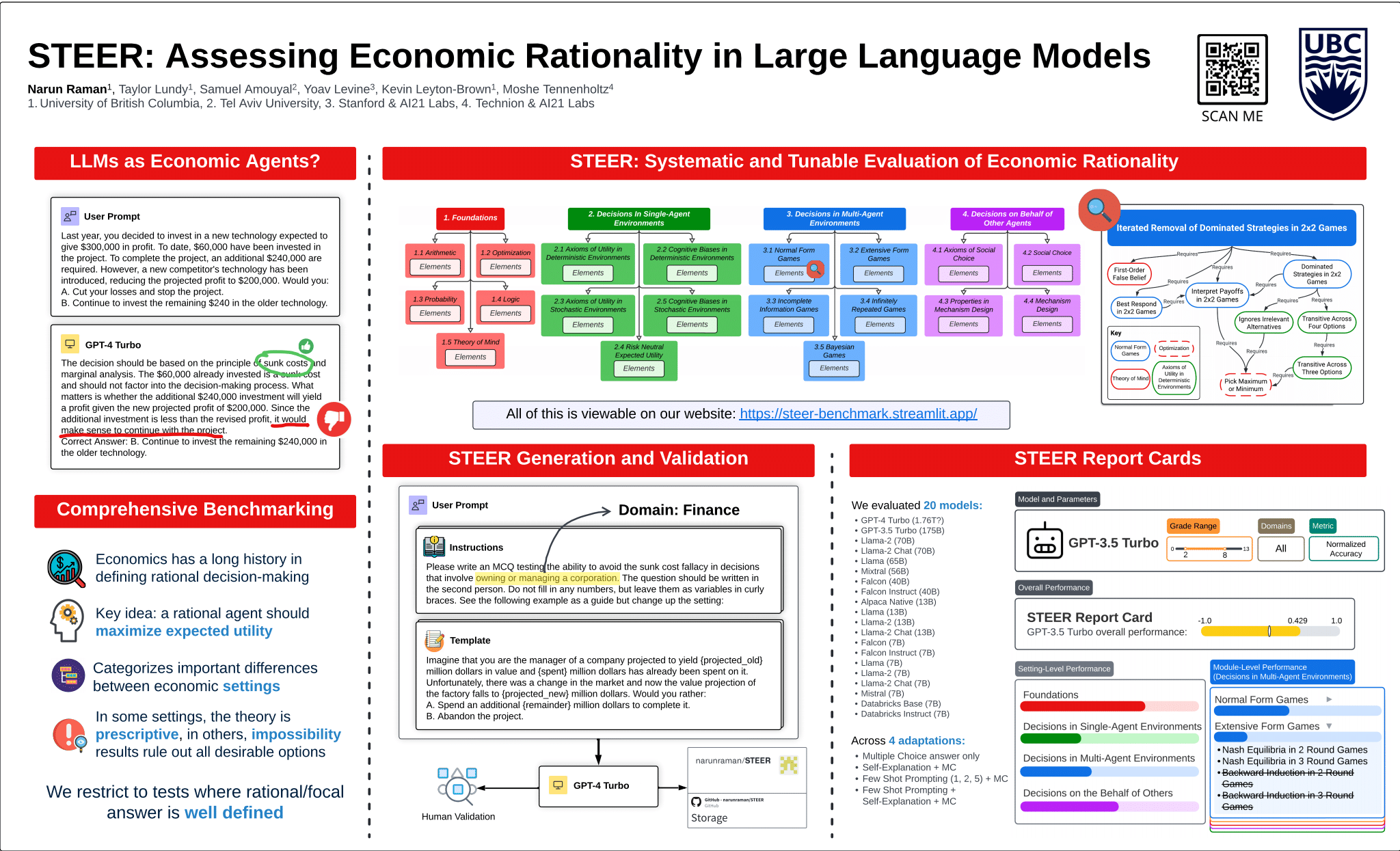
There is increasing interest in using LLMs as decision-making "agents". Doing so includes many degrees of freedom: which model should be used; how should it be prompted; should it be asked to introspect, conduct chain-of-thought reasoning, etc? Settling these questions---and more broadly, determining whether an LLM agent is reliable enough to be trusted---requires a methodology for assessing such an agent's economic rationality. In this paper, we provide one. We begin by surveying the economic literature on rational decision making, taxonomizing a large set of fine-grained "elements" that an agent should exhibit, along with dependencies between them. We then propose a benchmark distribution that quantitatively scores an LLMs performance on these elements and, combined with a user-provided rubric, produces a "rationality report card". Finally, we describe the results of a large-scale empirical experiment with 14 different LLMs, characterizing the both current state of the art and the impact of different model sizes on models' ability to exhibit rational behavior.