Efficient Exploration in Average-Reward Constrained Reinforcement Learning: Achieving Near-Optimal Regret With Posterior Sampling
Danil Provodin ⋅ Maurits Kaptein ⋅ Mykola Pechenizkiy
2024 Poster
{kind=link}
Abstract
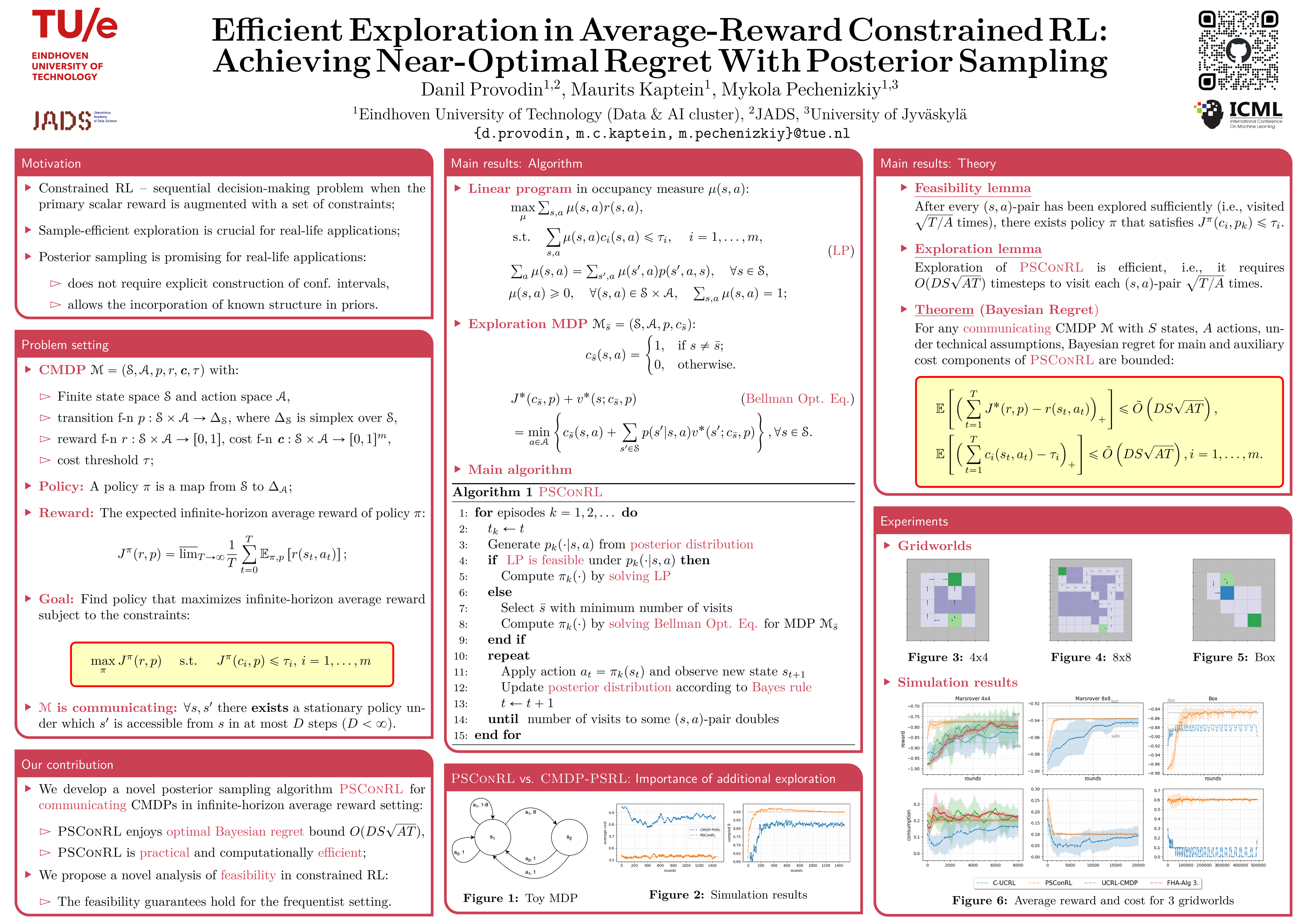
We present a new algorithm based on posterior sampling for learning in Constrained Markov Decision Processes (CMDP) in the infinite-horizon undiscounted setting. The algorithm achieves near-optimal regret bounds while being advantageous empirically compared to the existing algorithms. Our main theoretical result is a Bayesian regret bound for each cost component of $\tilde{O} (DS\sqrt{AT})$ for any communicating CMDP with $S$ states, $A$ actions, and diameter $D$. This regret bound matches the lower bound in order of time horizon $T$ and is the best-known regret bound for communicating CMDPs achieved by a computationally tractable algorithm. Empirical results show that our posterior sampling algorithm outperforms the existing algorithms for constrained reinforcement learning.
Chat is not available.
Successful Page Load