SAM-E: Leveraging Visual Foundation Model with Sequence Imitation for Embodied Manipulation
{kind=link}
Abstract
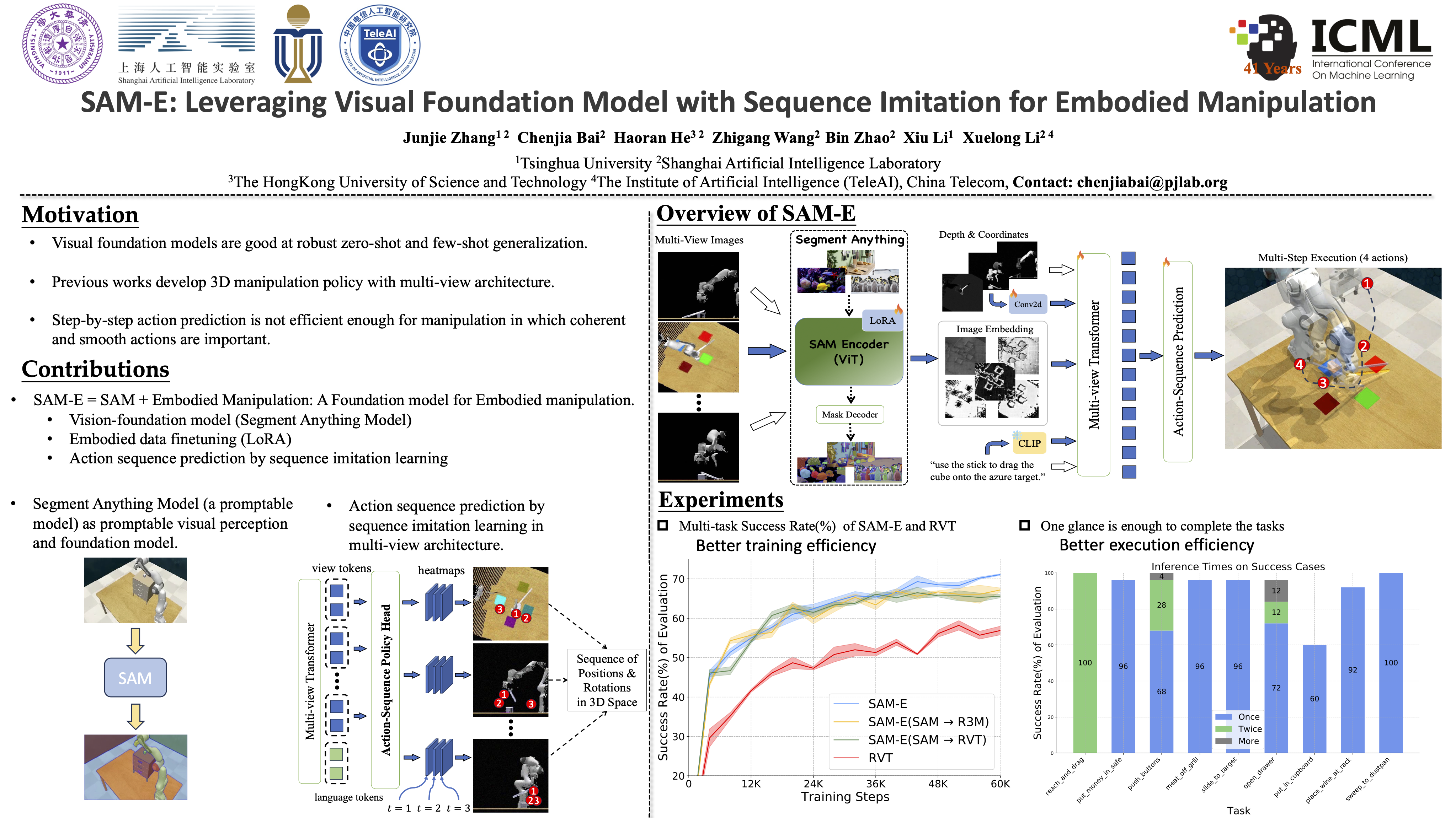
Acquiring a multi-task imitation policy in 3D manipulation poses challenges in terms of scene understanding and action prediction. Current methods employ both 3D representation and multi-view 2D representation to predict the poses of the robot’s end-effector. However, they still require a considerable amount of high-quality robot trajectories, and suffer from limited generalization in unseen tasks and inefficient execution in long-horizon reasoning. In this paper, we propose SAM-E, a novel architecture for robot manipulation by leveraging a vision-foundation model for generalizable scene understanding and sequence imitation for long-term action reasoning. Specifically, we adopt Segment Anything (SAM) pre-trained on a huge number of images and promptable masks as the foundation model for extracting task-relevant features, and employ parameter-efficient fine-tuning on robot data for a better understanding of embodied scenarios. To address long-horizon reasoning, we develop a novel multi-channel heatmap that enables the prediction of the action sequence in a single pass, notably enhancing execution efficiency. Experimental results from various instruction-following tasks demonstrate that SAM-E achieves superior performance with higher execution efficiency compared to the baselines, and also significantly improves generalization in few-shot adaptation to new tasks.