Accelerated Speculative Sampling Based on Tree Monte Carlo
{kind=link}
Abstract
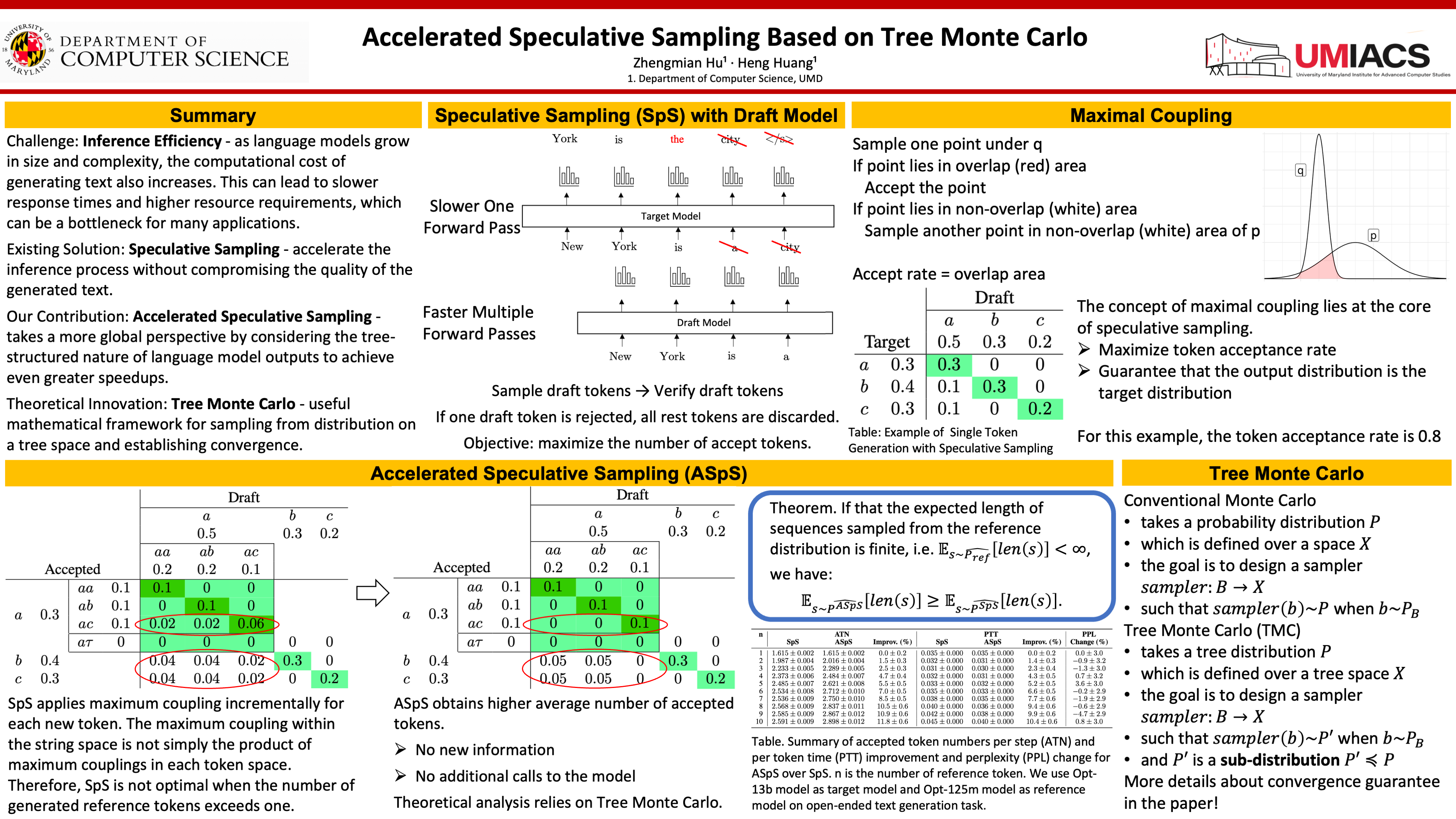
Speculative Sampling (SpS) has been introduced to speed up inference of large language models (LLMs) by generating multiple tokens in a single forward pass under the guidance of a reference model, while preserving the original distribution. We observe that SpS can be derived through maximum coupling on the token distribution. However, we find that this approach is not optimal as it applies maximum coupling incrementally for each new token, rather than seeking a global maximum coupling that yields a faster algorithm, given the tree-space nature of LLM generative distributions. In this paper, we shift our focus from distributions on a token space to those on a tree space. We propose a novel class of Tree Monte Carlo (TMC) methods, demonstrating their unbiasedness and convergence. As a particular instance of TMC, our new algorithm, Accelerated Speculative Sampling (ASpS), outperforms traditional SpS by generating more tokens per step on average, achieving faster inference, while maintaining the original distribution.