Advancing Dynamic Sparse Training by Exploring Optimization Opportunities
Jie Ji ⋅ Gen Li ⋅ Lu Yin ⋅ Minghai Qin ⋅ Geng Yuan ⋅ Linke Guo ⋅ Shiwei Liu ⋅ Xiaolong Ma
2024 Poster
{kind=link}
Abstract
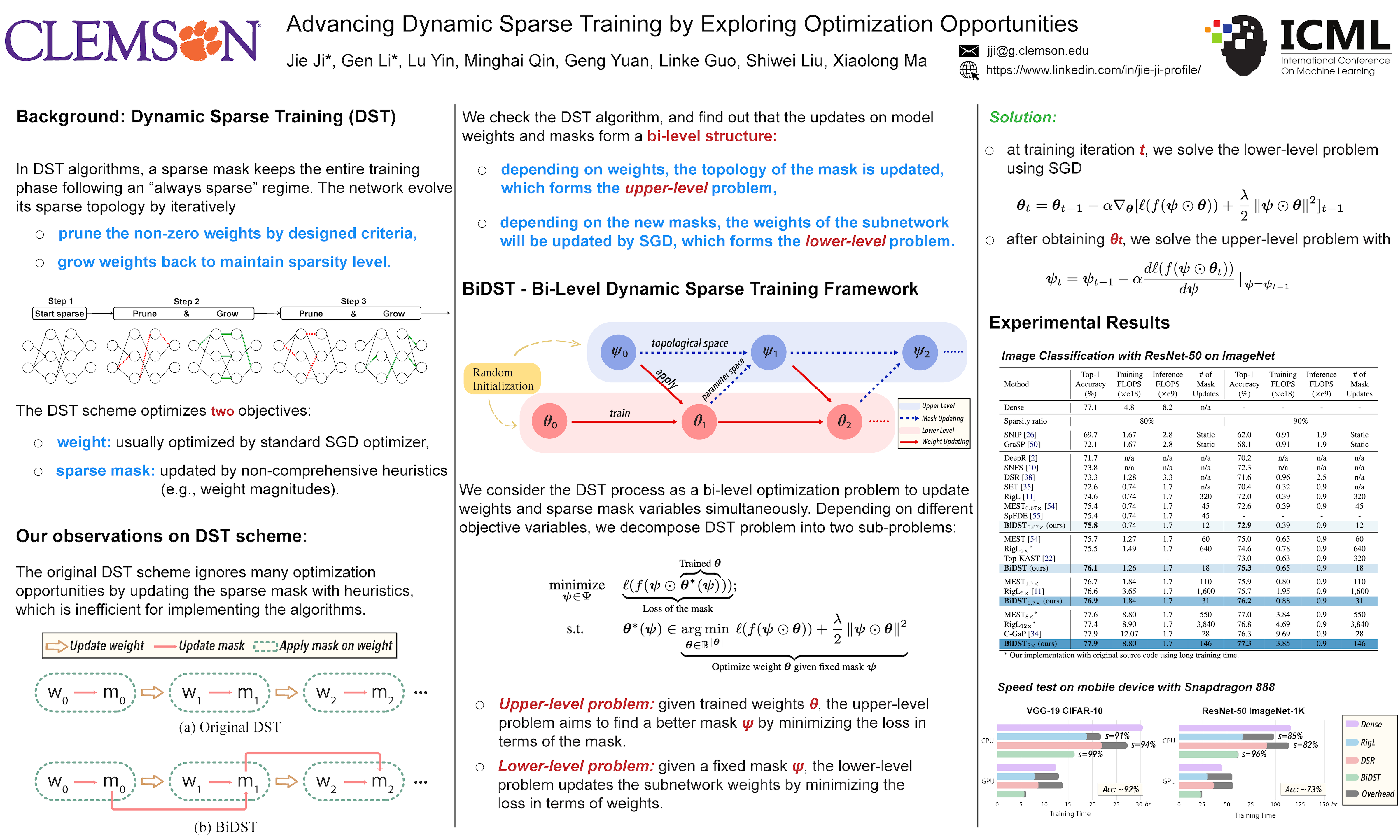
Dynamic Sparse Training (DST) is an effective approach for addressing the substantial training resource requirements posed by the ever-increasing size of the Deep Neural Networks (DNNs). Characterized by its dynamic "train-prune-grow'' schedule during training, DST implicitly develops a bi-level structure for training the weights while discovering a subnetwork topology. However, such a structure is consistently overlooked by the current DST algorithms for further optimization opportunities, and these algorithms, on the other hand, solely optimize the weights while determining masks heuristically. In this paper, we extensively study DST algorithms and argue that the training scheme of DST naturally forms a bi-level problem in which the updating of weight and mask is interdependent. Based on this observation, we introduce a novel efficient training framework called BiDST, which for the first time, introduces bi-level optimization methodology into dynamic sparse training domain. Unlike traditional partial-heuristic DST schemes, which suffer from sub-optimal search efficiency for masks and miss the opportunity to fully explore the topological space of neural networks, BiDST excels at discovering excellent sparse patterns by optimizing mask and weight simultaneously, resulting in maximum 2.62% higher accuracy, 2.1$\times$ faster execution speed, and 25$\times$ reduced overhead. Code available at https://github.com/jjsrf/BiDST-ICML2024.
Chat is not available.
Successful Page Load