Get More with LESS: Synthesizing Recurrence with KV Cache Compression for Efficient LLM Inference
{kind=link}
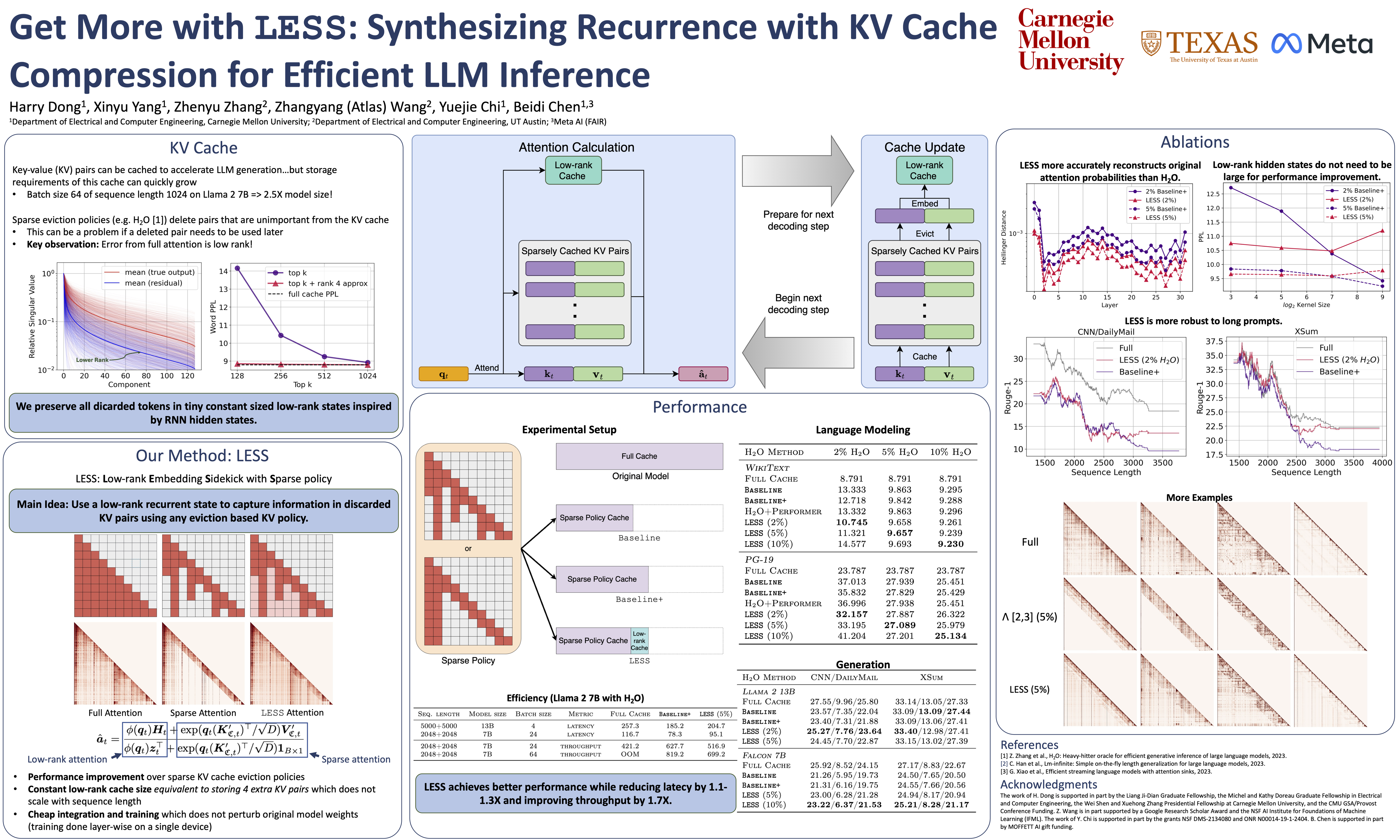
Abstract
Many computational factors limit broader deployment of large language models. In this paper, we focus on a memory bottleneck imposed by the key-value (KV) cache, a computational shortcut that requires storing previous KV pairs during decoding. While existing KV cache methods approach this problem by pruning or evicting large swaths of relatively less important KV pairs to dramatically reduce the memory footprint of the cache, they can have limited success in tasks that require recollecting a majority of previous tokens. To alleviate this issue, we propose LESS, a simple integration of a (nearly free) constant sized cache with eviction-based cache methods, such that all tokens can be queried at later decoding steps. Its ability to retain information throughout time shows merit on a variety of tasks where we demonstrate LESS can help reduce the performance gap from caching everything, sometimes even matching it, all while being efficient. Relevant code can be found at https://github.com/hdong920/LESS.