VerityMath: Advancing Mathematical Reasoning by Self-Verification Through Unit Consistency
{kind=link}
Abstract
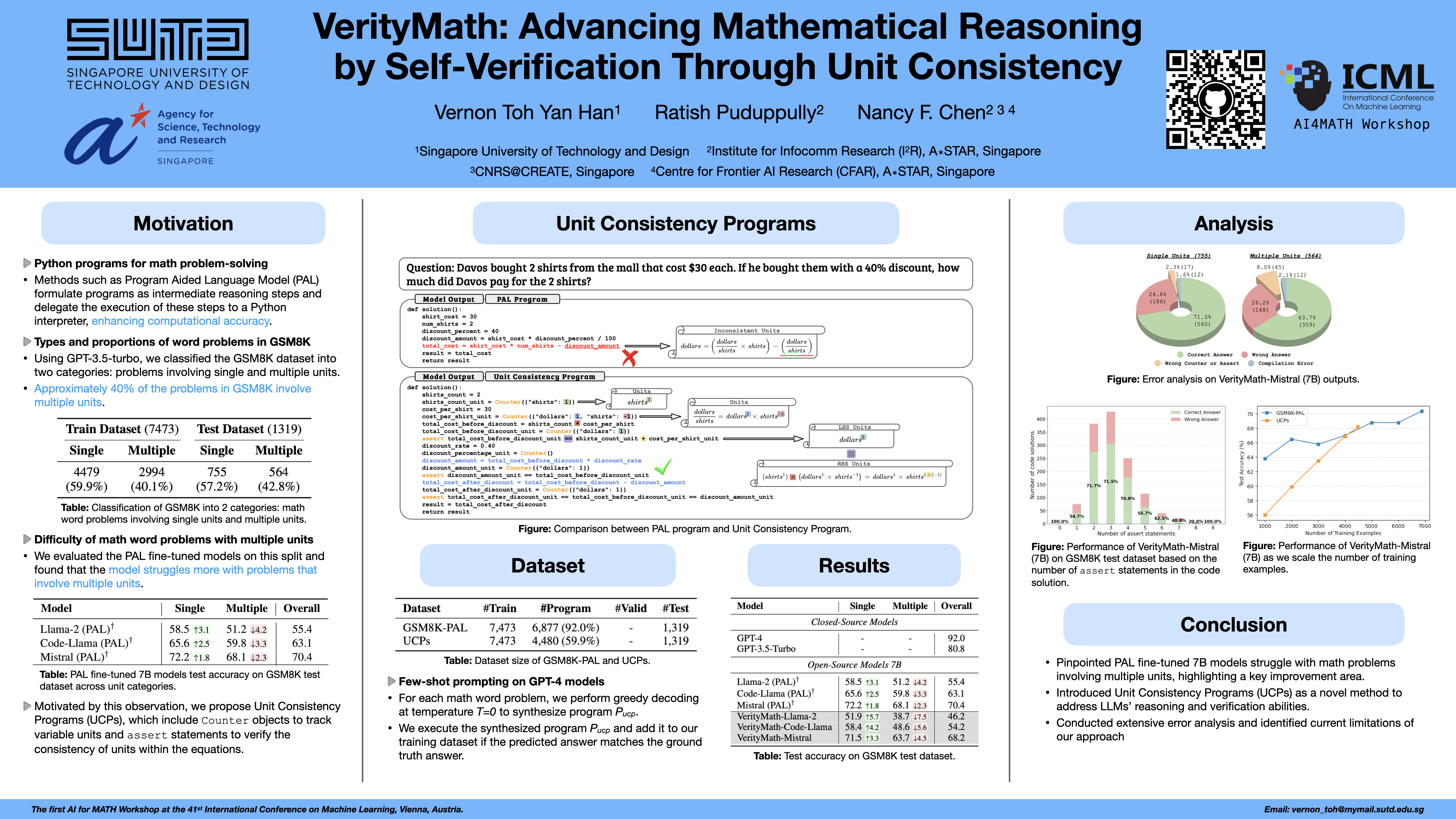
Large Language Models (LLMs), combined with program-based solving techniques, are increasingly demonstrating proficiency in mathematical reasoning. For example, closed-source models such as OpenAI GPT-4 and Claude show excellent results in solving math word problems. However, progress in math word problem-solving for open-source LLMs is limited, and the challenges these models face are not well-studied. In this paper, we study the performance of strong open-source LLMs, including Llama 2 (7B), Code Llama (7B), and Mistral (7B) on math word problems using program-based solving techniques. Specifically, we analyze the outputs of these models when applied to math word problems and identify a category of problems that pose a significant challenge, particularly those involving quantities spanning multiple units. To address this issue, we propose a systematic approach by defining the units for each quantity and ensuring the consistency of these units during mathematical operations. We developed Unit Consistency Programs (UCPs), an annotated dataset of math word problems, each paired with programs containing unit specifications and unit verification routines. We fine-tuned Llama 2 (7B), Code Llama (7B), and Mistral (7B) models with UCPs to produce their VerityMath variants. Our findings indicate that our approach, which incorporates unit consistency, currently slightly underperforms compared to an approach that does not. To understand the reasons behind this, we conducted an in-depth error analysis and suggested options for future improvements.