Snapshot Reinforcement Learning: Leveraging Prior Trajectories for Efficiency
in
Workshop: Automated Reinforcement Learning: Exploring Meta-Learning, AutoML, and LLMs
{kind=link}
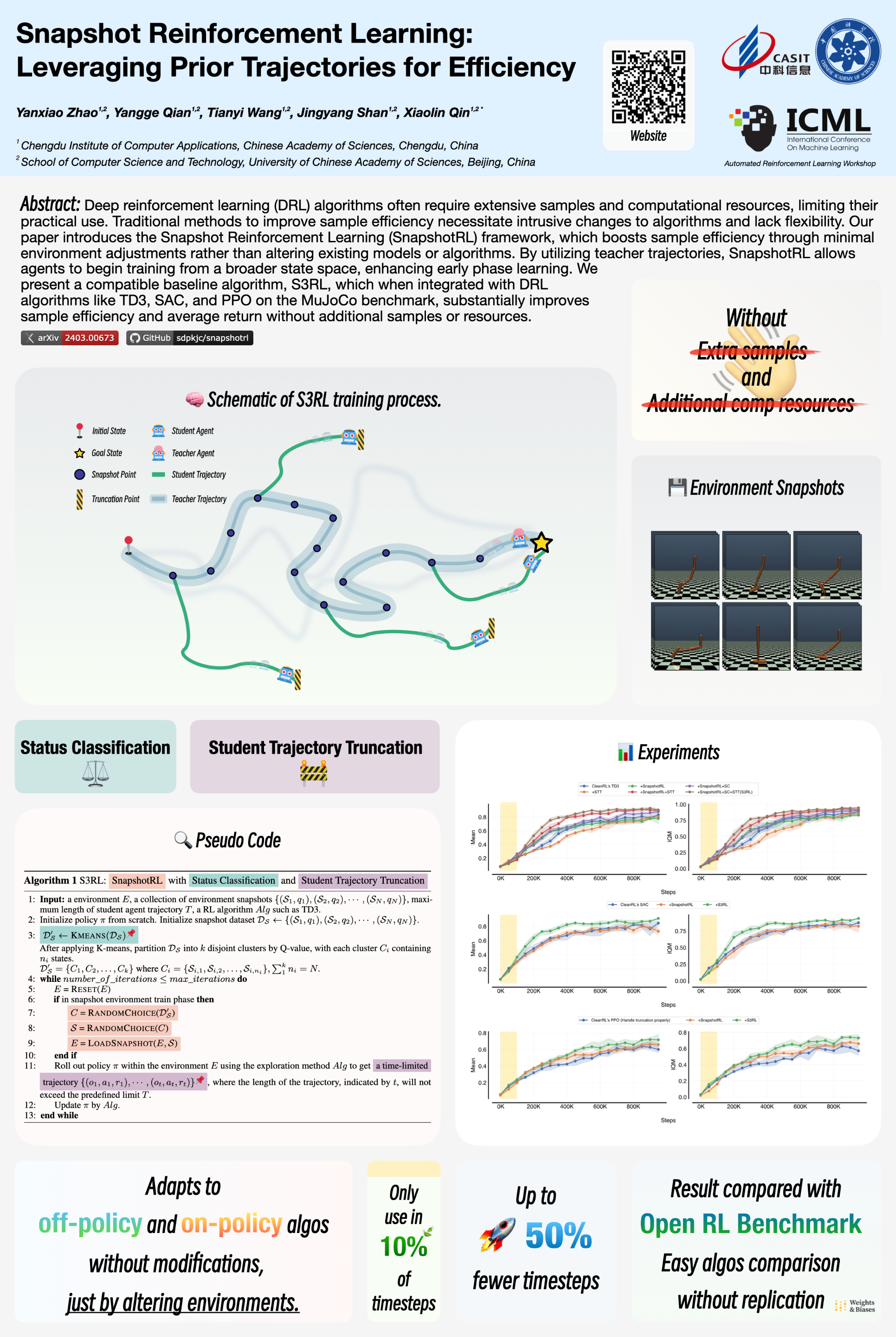
Abstract
Deep reinforcement learning (DRL) algorithms require substantial samples and computational resources to achieve higher performance, which restricts their practical application and poses challenges for further development. Given the constraint of limited resources, it is essential to leverage existing computational work (e.g., learned policies, samples) to enhance sample efficiency and reduce the computational resource consumption of DRL algorithms. Previous works to leverage existing computational work require intrusive modifications to existing algorithms and models, designed specifically for specific algorithms, lacking flexibility and universality. In this paper, we present the Snapshot Reinforcement Learning (SnapshotRL) framework, which enhances sample efficiency by simply altering environments, without making any modifications to algorithms and models. By allowing student agents to choose states in teacher trajectories as the initial state to sample, SnapshotRL can effectively utilize teacher trajectories to assist student agents in training, allowing student agents to explore a larger state space at the early training phase. We propose a simple and effective SnapshotRL baseline algorithm, S3RL, which integrates well with existing DRL algorithms. Our experiments demonstrate that integrating S3RL with TD3, SAC, and PPO algorithms on the MuJoCo benchmark significantly improves sample efficiency and average return, without extra samples and additional computational resources.