Implicit Jacobian regularization weighted with impurity of probability output
Sungyoon Lee ⋅ Jinseong Park ⋅ Jaewook Lee
2023 Poster
{kind=link}
Abstract
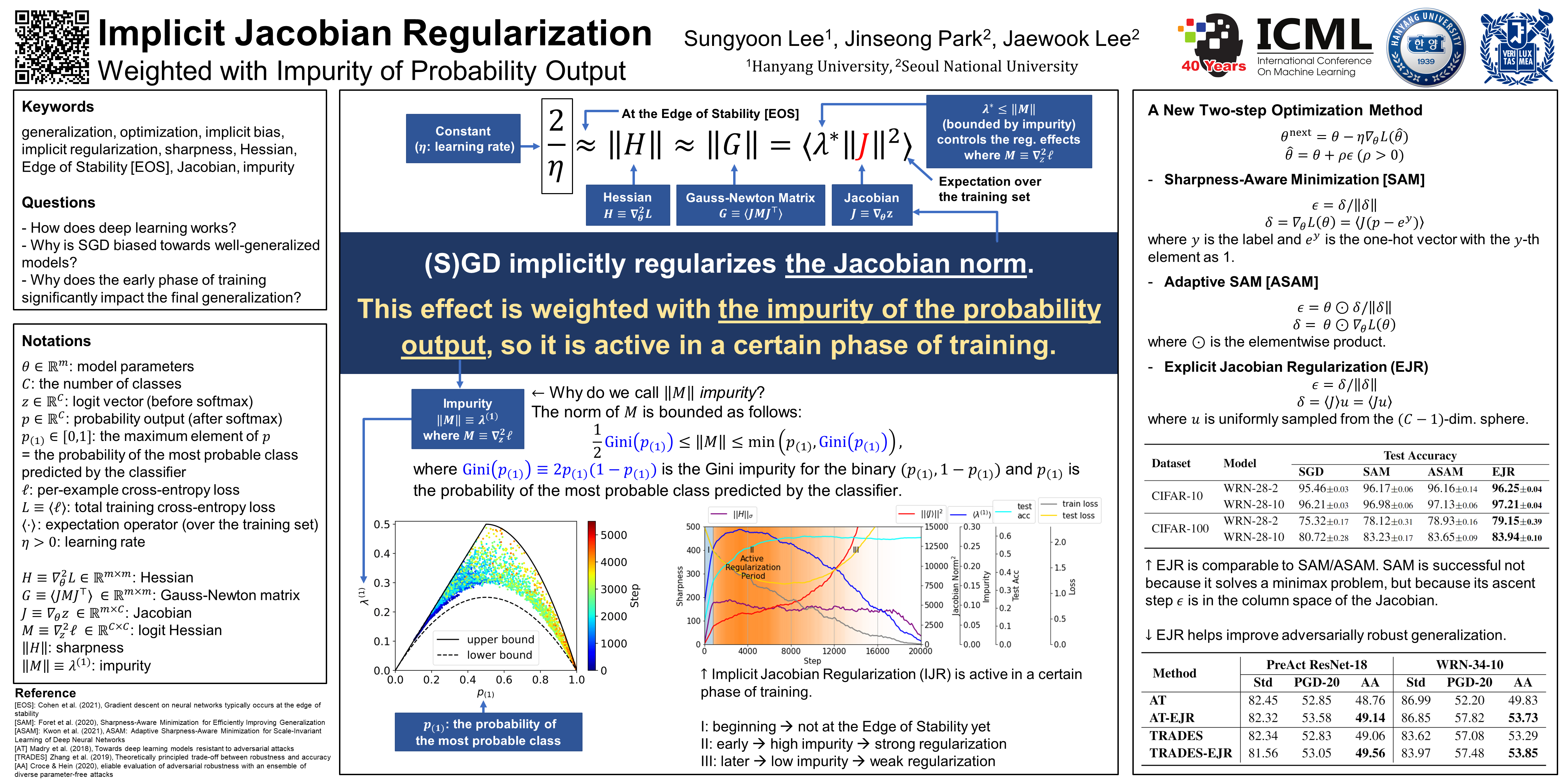
The success of deep learning is greatly attributed to stochastic gradient descent (SGD), yet it remains unclear how SGD finds well-generalized models. We demonstrate that SGD has an implicit regularization effect on the logit-weight Jacobian norm of neural networks. This regularization effect is weighted with the impurity of the probability output, and thus it is active in a certain phase of training. Moreover, based on these findings, we propose a novel optimization method that explicitly regularizes the Jacobian norm, which leads to similar performance as other state-of-the-art sharpness-aware optimization methods.
Video
Chat is not available.
Successful Page Load