Flipping Coins to Estimate Pseudocounts for Exploration in Reinforcement Learning
Sam Lobel ⋅ Akhil Bagaria ⋅ George Konidaris
2023 Poster
{kind=link}
Abstract
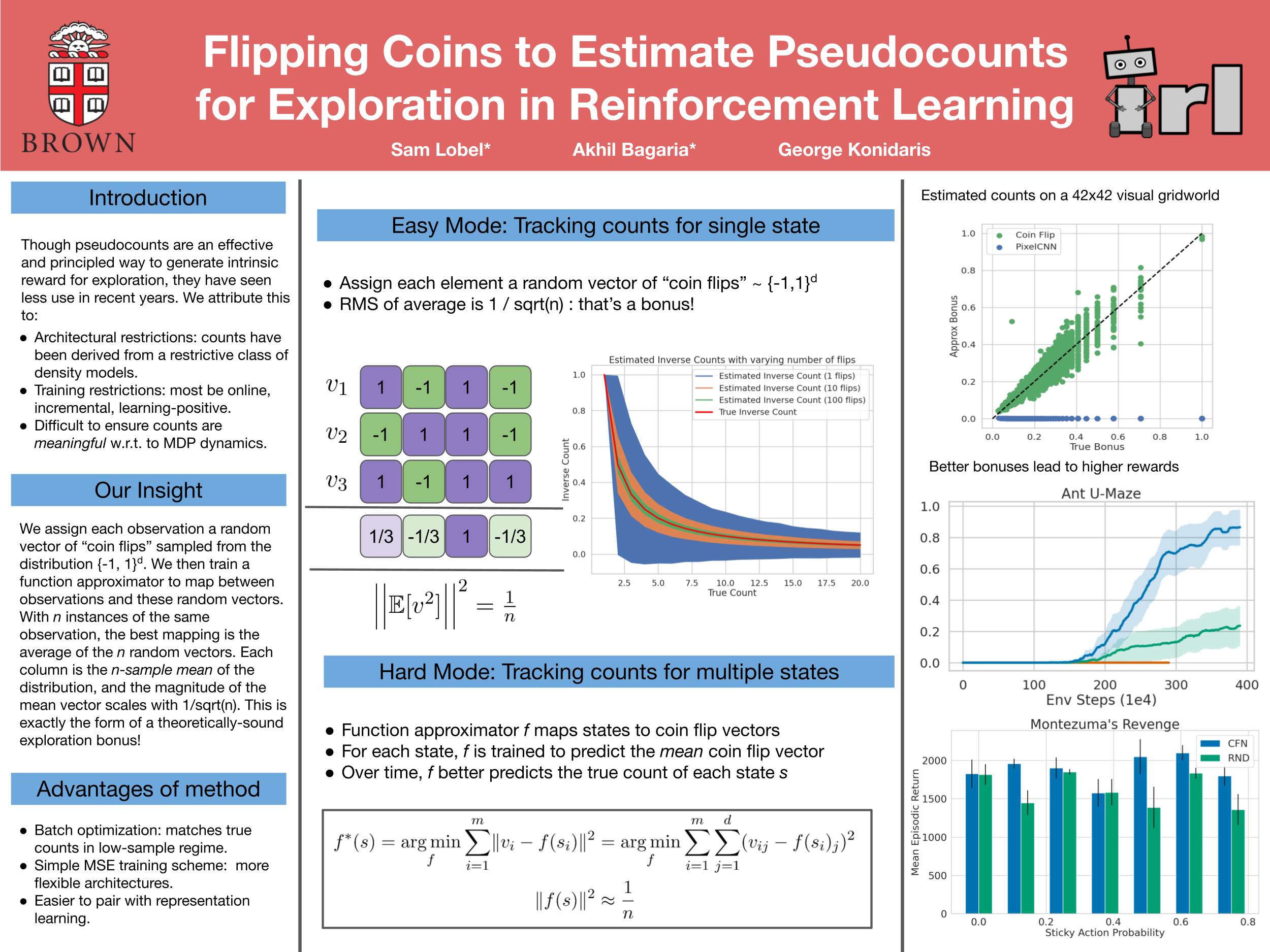
We propose a new method for count-based exploration in high-dimensional state spaces. Unlike previous work which relies on density models, we show that counts can be derived by averaging samples from the Rademacher distribution (or coin flips). This insight is used to set up a simple supervised learning objective which, when optimized, yields a state's visitation count. We show that our method is significantly more effective at deducing ground-truth visitation counts than previous work; when used as an exploration bonus for a model-free reinforcement learning algorithm, it outperforms existing approaches on most of 9 challenging exploration tasks, including the Atari game Montezuma's Revenge.
Video
Chat is not available.
Successful Page Load