Bridging the Gap: From Post Hoc Explanations to Inherently Interpretable Models for Medical Imaging
{kind=link}
Abstract
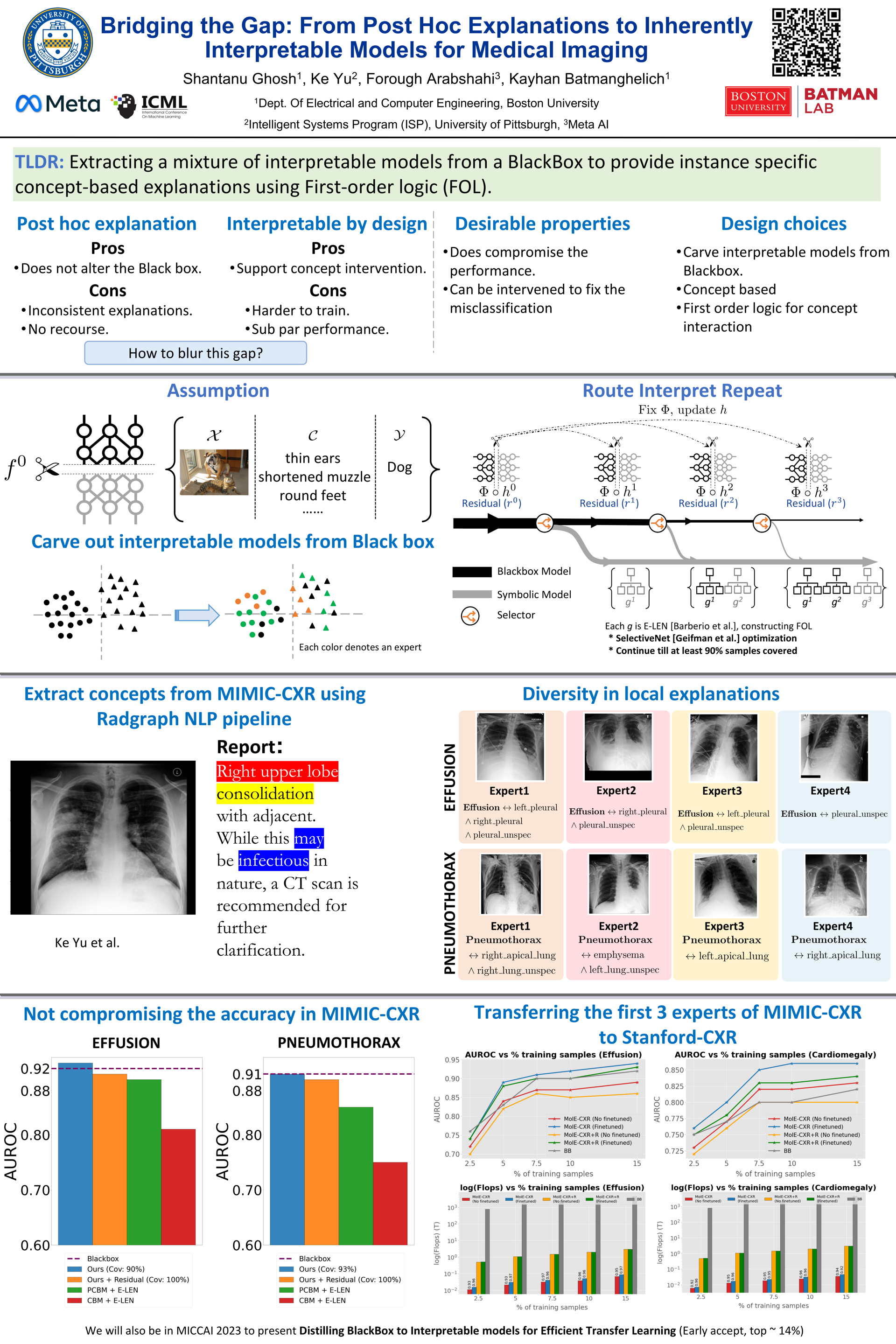
ML model design either starts with an interpretable model or a Blackbox (BB) and explains it post hoc. BB models are flexible but difficult to explain, while interpretable models are inherently explainable. Yet, interpretable models require extensive ML knowledge and tend to be less flexible and underperforming than their BB variants. This paper aims to blur the distinction between a post hoc explanation of a BB and constructing interpretable models. Beginning with a BB, we iteratively \emph{carve out} a mixture of interpretable experts and a \emph{residual network}. Each interpretable model specializes in a subset of samples and explains them using First Order Logic (FOL). We route the remaining samples through a flexible residual. We repeat the method on the residual network until all the interpretable models explain the desired proportion of data. Our extensive experiments show that our approach (1) identifies a diverse set of instance-specific concepts without compromising the performance of the BB, (2) identifies the relatively ``harder'' samples to explain via residuals, and (3) is transferred to an unknown target domain with limited data efficiently. The code is uploaded at \url{https://github.com/AI09-guy/IMLH-submission}.