Learning to Reach Goals via Diffusion
{kind=link}
Abstract
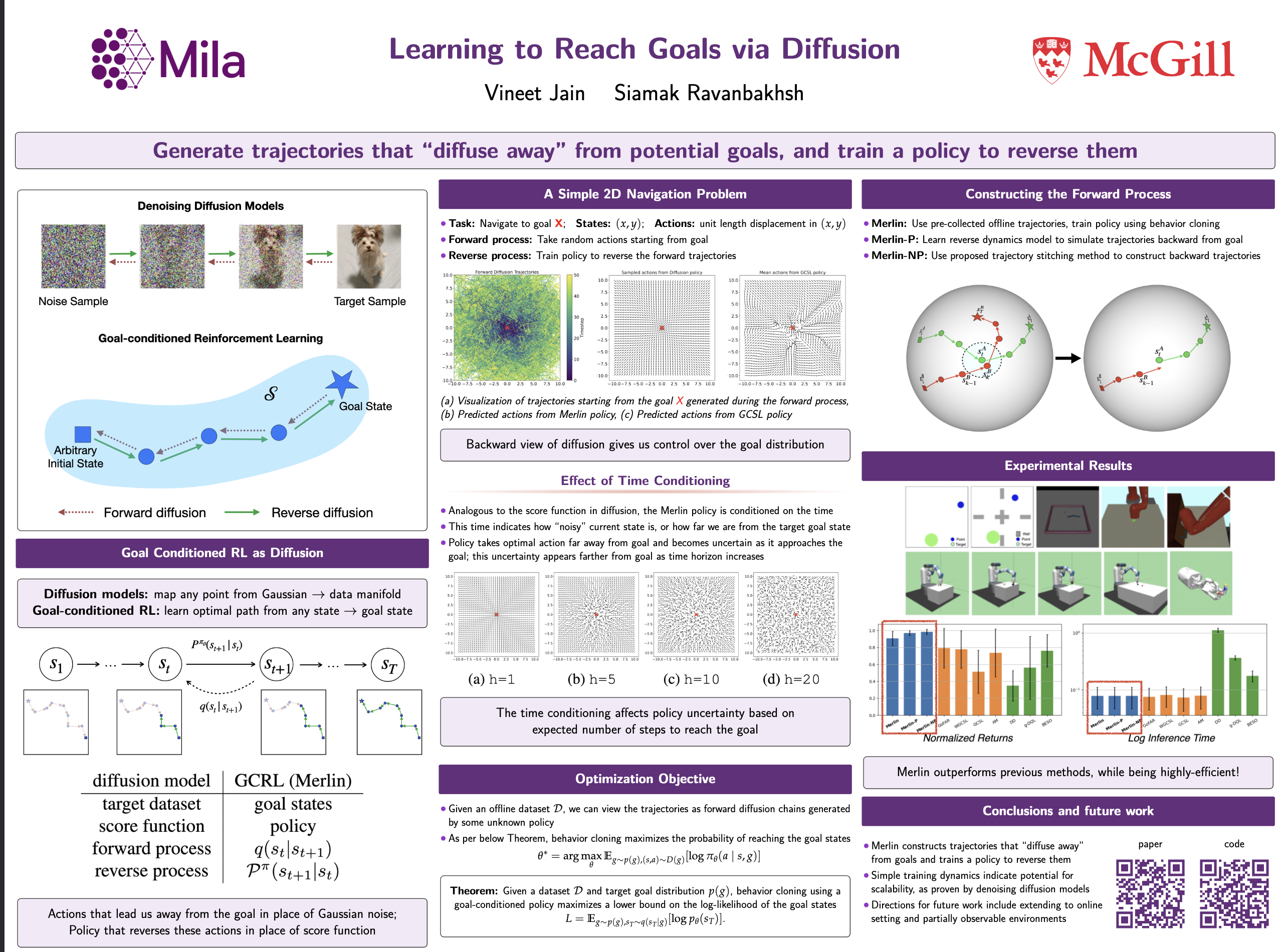
We present a novel perspective on goal-conditioned reinforcement learning by framing it within the context of denoising diffusion models. Analogous to the diffusion process, where Gaussian noise is used to create random trajectories that walk away from the data manifold, we construct trajectories that move away from potential goal states. We then learn a goal-conditioned policy to reverse these deviations, analogous to the score function. This approach, which we call Merlin, can reach specified goals from arbitrary initial states without learning a separate value function. In contrast to recent works utilizing diffusion models in offline RL, Merlin stands out as the first method to perform diffusion in the state space, requiring only one "denoising" iteration per environment step. We experimentally validate our approach in various offline goal-reaching tasks, demonstrating substantial performance enhancements compared to state-of-the-art methods while improving computational efficiency over other diffusion-based RL methods by an order of magnitude. Our results suggest that this perspective on diffusion for RL is a simple and scalable approach for sequential decision making.