Offline-Boosted Actor-Critic: Adaptively Blending Optimal Historical Behaviors in Deep Off-Policy RL
{kind=link}
Abstract
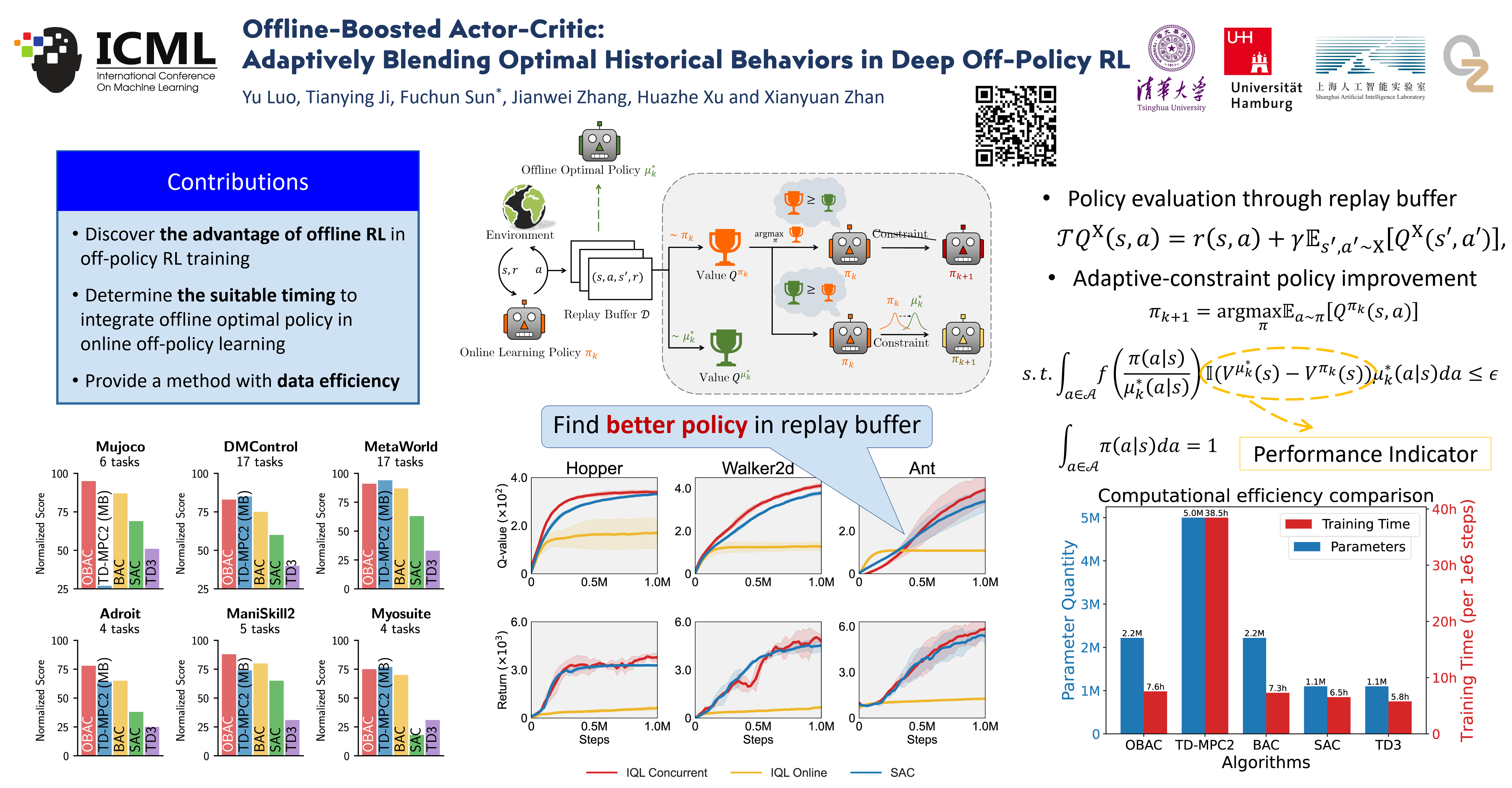
Off-policy reinforcement learning (RL) has achieved notable success in tackling many complex real-world tasks, by leveraging previously collected data for policy learning. However, most existing off-policy RL algorithms fail to maximally exploit the information in the replay buffer, limiting sample efficiency and policy performance. In this work, we discover that concurrently training an offline RL policy based on the shared online replay buffer can sometimes outperform the original online learning policy, though the occurrence of such performance gains remains uncertain. This motivates a new possibility of harnessing the emergent outperforming offline optimal policy to improve online policy learning. Based on this insight, we present Offline-Boosted Actor-Critic (OBAC), a model-free online RL framework that elegantly identifies the outperforming offline policy through value comparison, and uses it as an adaptive constraint to guarantee stronger policy learning performance. Our experiments demonstrate that OBAC outperforms other popular model-free RL baselines and rivals advanced model-based RL methods in terms of sample efficiency and asymptotic performance across 53 tasks spanning 6 task suites.