Unlocking the Power of Spatial and Temporal Information in Medical Multimodal Pre-training
{kind=link}
Abstract
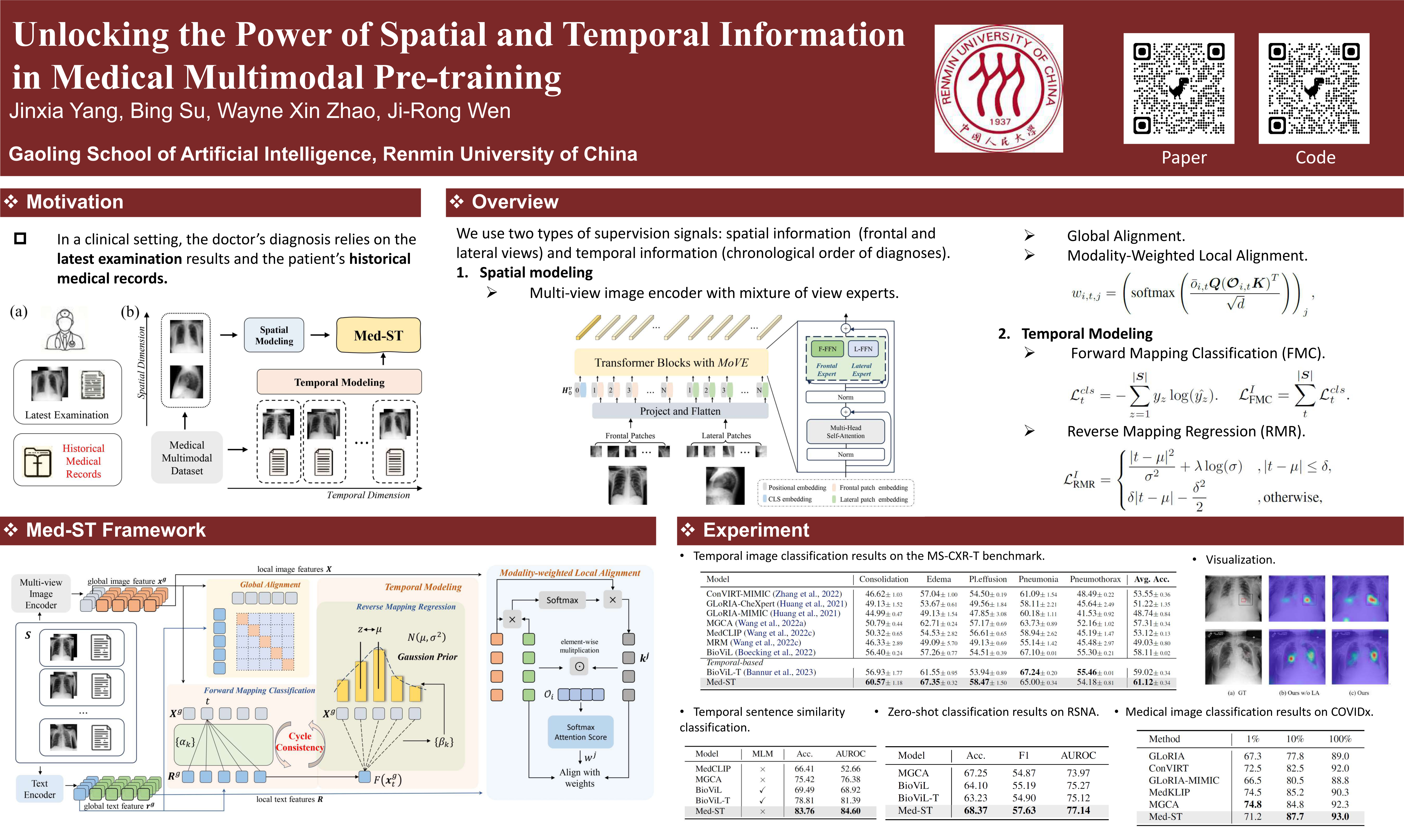
Medical vision-language pre-training methods mainly leverage the correspondence between paired medical images and radiological reports. Although multi-view spatial images and temporal sequences of image-report pairs are available in off-the-shelf multi-modal medical datasets, most existing methods have not thoroughly tapped into such extensive supervision signals. In this paper, we introduce the Med-ST framework for fine-grained spatial and temporal modeling to exploit information from multiple spatial views of chest radiographs and temporal historical records. For spatial modeling, Med-ST employs the Mixture of View Expert (MoVE) architecture to integrate different visual features from both frontal and lateral views. To achieve a more comprehensive alignment, Med-ST not only establishes the global alignment between whole images and texts but also introduces modality-weighted local alignment between text tokens and spatial regions of images. For temporal modeling, we propose a novel cross-modal bidirectional cycle consistency objective by forward mapping classification (FMC) and reverse mapping regression (RMR). By perceiving temporal information from simple to complex, Med-ST can learn temporal semantics. Experimental results across four distinct tasks demonstrate the effectiveness of Med-ST, especially in temporal classification tasks. Our code and model are available at https://github.com/SVT-Yang/MedST.