DéjàVu: KV-cache Streaming for Fast, Fault-tolerant Generative LLM Serving
Foteini Strati ⋅ Sara McAllister ⋅ Amar Phanishayee ⋅ Jakub Tarnawski ⋅ Ana Klimovic
2024 Poster
{kind=link}
Abstract
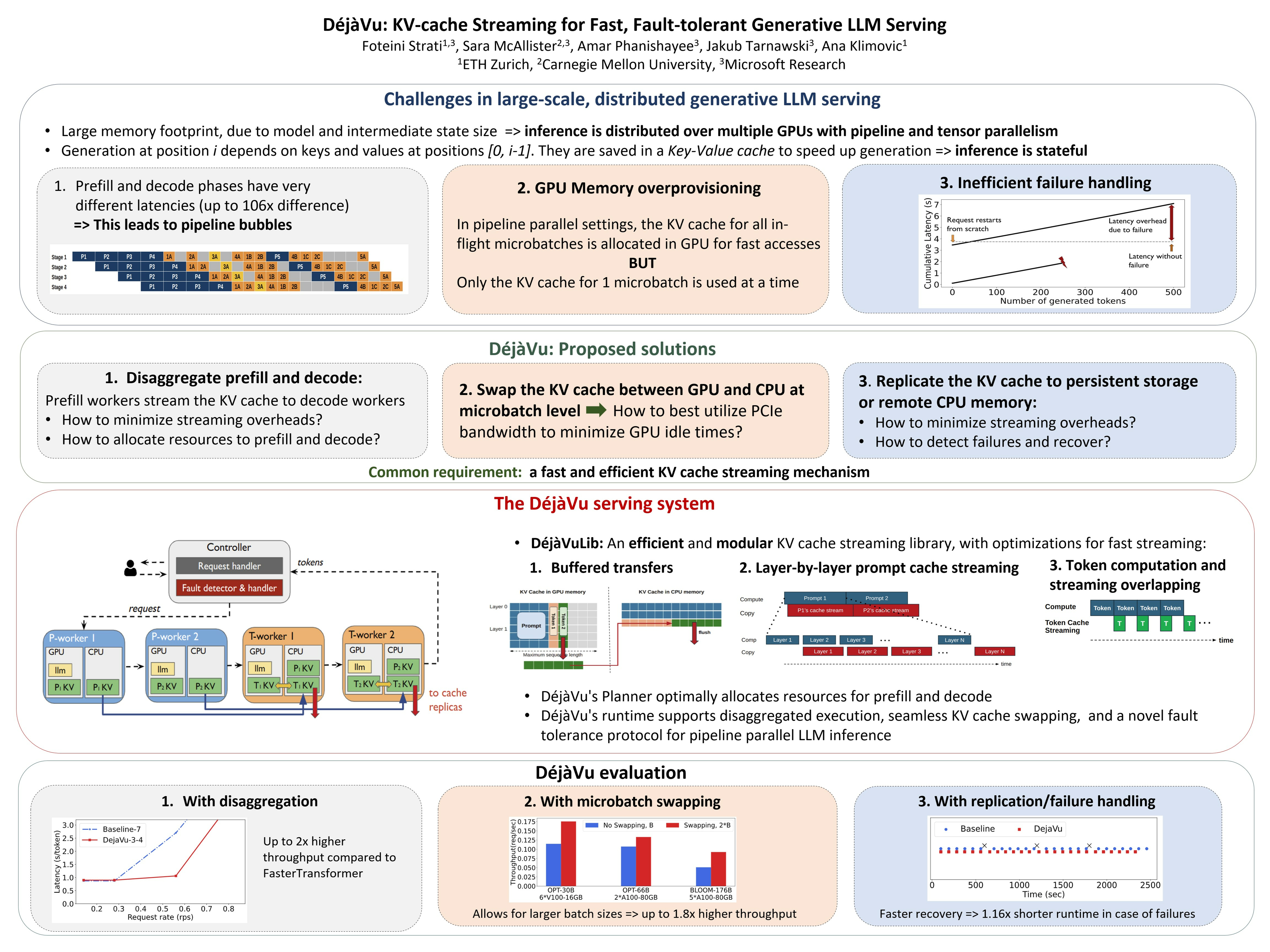
Distributed LLM serving is costly and often underutilizes hardware accelerators due to three key challenges: bubbles in pipeline-parallel deployments caused by the bimodal latency of prompt and token processing, GPU memory overprovisioning, and long recovery times in case of failures. DéjàVu addresses all these challenges using a versatile and efficient KV cache streaming library (DéjàVuLib). Using DéjàVuLib, we propose and implement efficient prompt-token disaggregation to reduce pipeline bubbles, microbatch swapping for efficient GPU memory management, and state replication for fault-tolerance. We highlight the efficacy of these solutions on a range of large models across cloud deployments.
Chat is not available.
Successful Page Load