Debiased Offline Representation Learning for Fast Online Adaptation in Non-stationary Dynamics
{kind=link}
Abstract
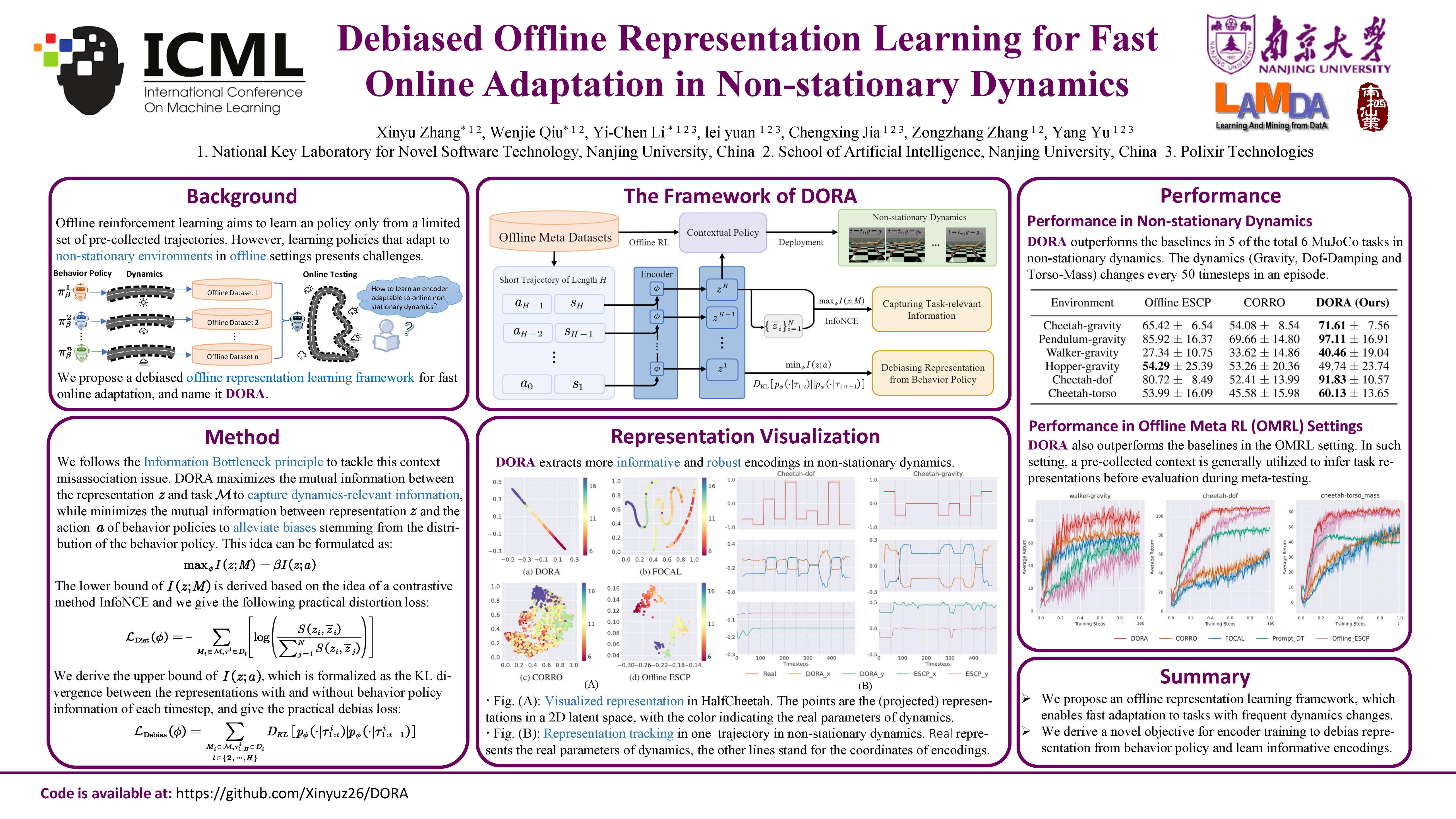
Developing policies that can adapt to non-stationary environments is essential for real-world reinforcement learning applications. Nevertheless, learning such adaptable policies in offline settings, with only a limited set of pre-collected trajectories, presents significant challenges. A key difficulty arises because the limited offline data makes it hard for the context encoder to differentiate between changes in the environment dynamics and shifts in the behavior policy, often leading to context misassociations. To address this issue, we introduce a novel approach called debiased offline representation learning for fast online adaptation (DORA). DORA incorporates an information bottleneck principle that maximizes mutual information between the dynamics encoding and the environmental data, while minimizing mutual information between the dynamics encoding and the actions of the behavior policy. We present a practical implementation of DORA, leveraging tractable bounds of the information bottleneck principle. Our experimental evaluation across six benchmark MuJoCo tasks with variable parameters demonstrates that DORA not only achieves a more precise dynamics encoding but also significantly outperforms existing baselines in terms of performance.