Adapting Pretrained ViTs with Convolution Injector for Visuo-Motor Control
{kind=link}
Abstract
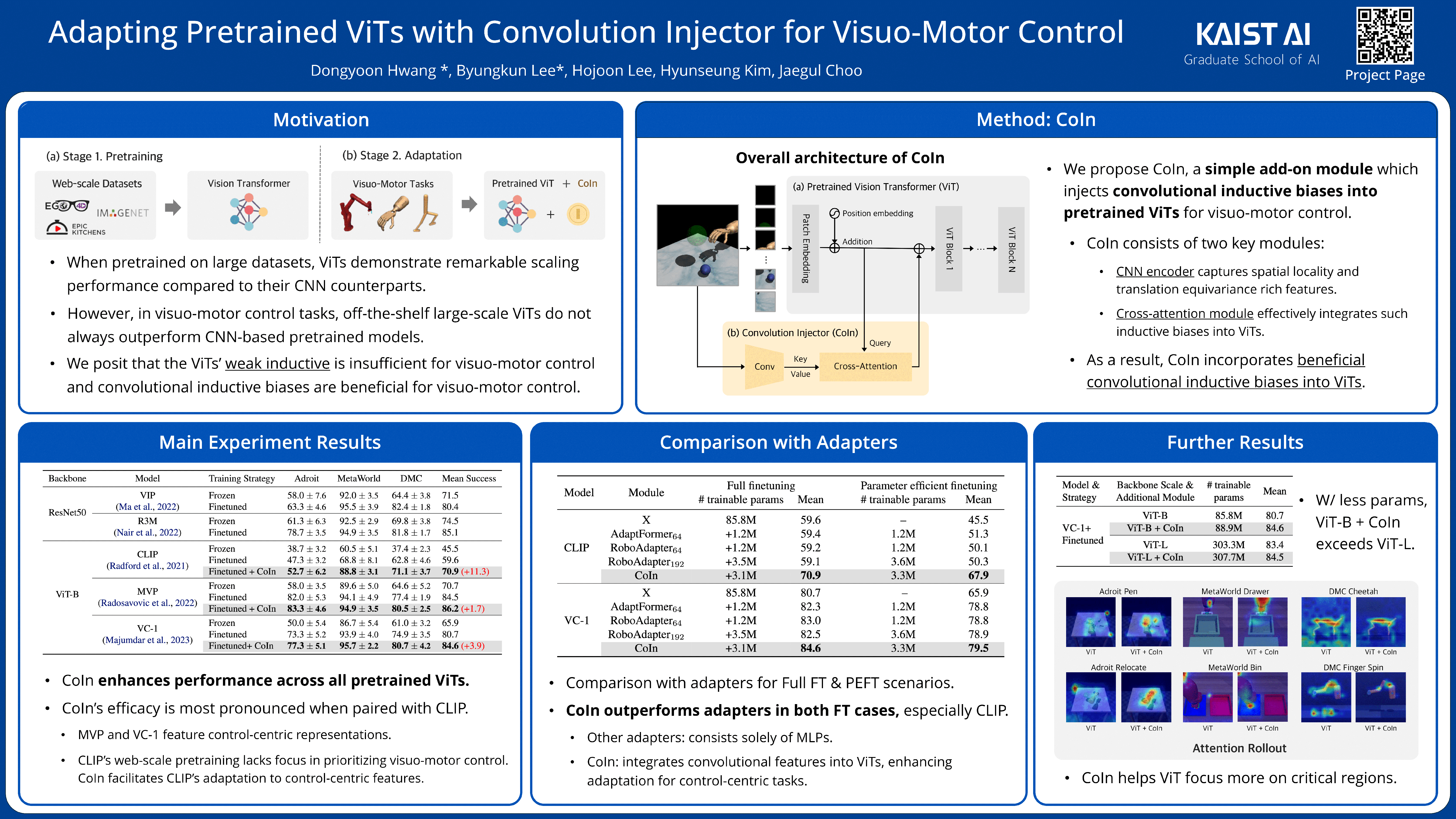
Vision Transformers (ViT), when paired with large-scale pretraining, have shown remarkable performance across various computer vision tasks, primarily due to their weak inductive bias. However, while such weak inductive bias aids in pretraining scalability, this may hinder the effective adaptation of ViTs for visuo-motor control tasks as a result of the absence of control-centric inductive biases. Such absent inductive biases include spatial locality and translation equivariance bias which convolutions naturally offer. To this end, we introduce Convolution Injector (CoIn), an add-on module that injects convolutions which are rich in locality and equivariance biases into a pretrained ViT for effective adaptation in visuo-motor control. We evaluate CoIn with three distinct types of pretrained ViTs (CLIP, MVP, VC-1) across 12 varied control tasks within three separate domains (Adroit, MetaWorld, DMC), and demonstrate that CoIn consistently enhances control task performance across all experimented environments and models, validating the effectiveness of providing pretrained ViTs with control-centric biases.